
Google에서 유사한 지역 법인을 결정하는 방법
게시 됨: 2018-01-30
지역 검색은 지역적 의미가 있는 지역 엔터티로 가득 차 있습니다.
Google의 지역 검색은 자연 검색보다 의미 기반입니다. 2018년 1월 2일 Google에 부여된 특허에서와 같이 기업을 종종 '로컬 엔티티'라고 하는 경우 페이지의 키워드. 부분적으로는 엔티티를 표시하는 지식 정보를 도입한 후 오늘날 Google에서 기업용 지식 패널을 보는 이유입니다. 해당 특허에 따른 지역 법인의 정의는 흥미롭습니다.
일부 검색 시스템은 검색 쿼리가 수신된 사용자 장치의 위치를 얻거나 추론할 수 있으며 검색 쿼리에 응답하는 로컬 검색 결과를 포함할 수 있습니다. 로컬 검색 결과는 로컬 엔터티를 설명하는 문서를 참조하는 검색 결과입니다. 지역 엔터티는 차례로 특정 위치에 대해 지역적으로 중요한 것으로 분류된 엔터티입니다. 로컬 엔티티는 일반적으로 레스토랑, 병원, 랜드마크 등과 같은 주소 또는 지역과 연관된 물리적 엔티티입니다. 로컬 엔티티를 설명하는 문서를 참조하는 검색 결과는 로컬 엔티티와 연관된 위치가 사용자 장치의 위치 근처에 있는 경우 쿼리에 대한 검색 점수 "부스트"를 수신합니다. 예를 들어, "커피숍"에 대한 검색 질의에 응답하여, 검색 시스템은 사용자 장치의 위치 근처에 있는 커피숍에 대한 웹 페이지를 참조하는 지역 검색 결과를 제공할 수 있습니다. 다양한 지역의 많은 사용자는 "커피숍"이라는 검색어를 제출하는 사용자가 다음과 같은 커피숍에 대한 검색 결과에 관심이 있을 가능성이 높기 때문에 "커피숍"이라는 검색어에 대한 응답으로 커피숍에 대한 지역 검색결과를 수신하는 데 만족할 것입니다. 사용자의 위치에 로컬입니다.
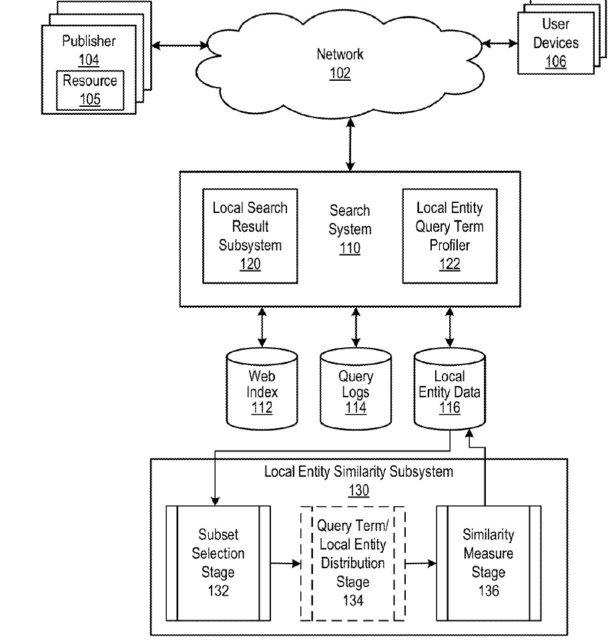
유사한 지역 엔티티를 표시하는 것이 목표입니다.
이 새로운 특허는 해당 엔터티와 관련된 쿼리에 대한 응답으로 로컬 엔터티의 순위를 매기는 것에 관한 것이 아닙니다. 또한 일부 검색은 유사한 결과를 표시하는 것을 기반으로 하는 검색 결과를 제공할 것이라고 알려줍니다. 이 또한 흥미롭습니다.
예를 들어, 지역 개체의 맥락에서 검색 엔진은 미리 결정된 방식으로 서로 관련되어 있는 지역 개체에 대한 검색 결과를 제공할 수 있습니다. 예를 들어, 음식점의 경우, 첫 번째 음식점을 참조하는 검색 결과를 선택하거나, 해당 음식점과 관련된 다른 음식점을 검색하여 유사한 가격에 유사한 메뉴를 제공하는 다른 음식점을 추천할 수 있습니다. 첫 번째 레스토랑.
들러서 커피를 마실 곳을 찾고 있다면 근처에 여러 커피 하우스를 볼 수 있고 멀리 떨어져있을지라도 한 곳은 더 가깝고 다른 곳은 가깝더라도 방문하고 싶은 곳을 결정할 수 있습니다. 조금 더 멀리. 내가 이 글을 읽기 시작했을 때 했던 질문은 Google이 다른 엔티티가 유사한지 결정하는 데 사용할 수 있는 것입니다. 그들은 어떻게 그것을 결정 했습니까? 지역 엔터티가 지리적 위치에 대해 지역적 중요성을 갖는지 어떻게 결정합니까?
특허는 이 특허의 프로세스가 혁신적인 측면을 갖도록 하는 몇 가지 요소를 알려줍니다. 여기에는 다음이 포함됩니다.
1) 로컬 엔티티 세트의 각 로컬 엔티티에 대해 지정하는 데이터 액세스, 여기서 각 로컬 엔티티는 지리적 위치로 확인된 물리적 엔티티이고, 장소.
2) 식별된 현지 법인 및 유사한 현지 법인의 유사성 측정인 유사성 측정을 결정합니다. 그들의 유사성은 그들을 관련이 있다고 간주하기에 충분할 수 있습니다.
특허는 다음과 같습니다.
관련 로컬 엔터티 감지
발명가: Kumar Mayur Thakur 및 Mukund Jha
양수인: Google Inc.
미국 특허 9,858,291
부여: 2018년 1월 2일
출원일: 2014년 10월 30일
추상적 인
로컬 엔티티를 처리하기 위한 컴퓨터 저장 매체에 인코딩된 컴퓨터 프로그램을 포함하는 방법, 시스템 및 장치. 일 양태에서, 방법은 로컬 엔티티들의 세트 내의 각각의 로컬 엔티티에 대한 쿼리 용어 및 쿼리 로그에서 발생하는 쿼리 용어를 포함하는 쿼리의 많은 인스턴스에 기초한 각 쿼리 용어에 대한 용어 값, 및 선택 값을 지정하는 데이터에 액세스하는 단계를 포함합니다. 쿼리 용어를 포함하고 쿼리 용어에 기인한 쿼리에 대한 응답으로 각각이 로컬 엔터티를 참조하는 검색 결과의 여러 선택에 기반합니다. 로컬 엔티티들의 세트로부터 제1 로컬 엔티티를 선택하는 단계; 로컬 엔티티의 세트로부터 제2 로컬 엔티티의 서브세트를 선택하는 단계; 및 서브세트 내의 각각의 제2 로컬 엔티티에 대해, 제1 로컬 엔티티에 대한 제2 로컬 엔티티의 유사성의 척도를 결정하는 단계를 포함한다.
로컬 엔티티에 대한 유사성은 어떻게 결정됩니까?
Google 지도의 지역 검색결과는 인용(링크와 리뷰는 인용.) 및 비즈니스용 웹사이트의 권위 점수.
이 새로운 특허는 Google이 특정 지역 검색결과와 함께 유사한 사이트를 표시하여 검색자에게 선택할 수 있는 옵션과 방문할 장소를 제공할 수 있음을 알려줍니다. 쿼리 및 설명에 나타나는 단어를 살펴보는 관점에서 유사도가 어떻게 결정되는지 설명합니다.
유사성 측정은 부분적으로 각 로컬 엔터티에 대한 쿼리 용어 데이터를 기반으로 합니다. 이 서면 설명에 사용된 쿼리 용어는 쿼리의 일부를 구성하는 n-그램일 수 있지만 전체 쿼리일 필요는 없습니다. 예를 들어, "Restaurant Review Gino's" 쿼리의 경우 쿼리 용어는 유니그램 "Restaurant", "Review" 및 "Gino's"일 수 있습니다. 바이그램, 트라이그램 등과 같은 다른 n-그램도 쿼리 용어로 사용할 수 있습니다.
언어 유사성을 찾는 것 외에도 Google은 특정 마일 반경 내에서 유사한 지역 엔터티를 찾을 수도 있습니다. 이것은 내가 지역 검색 결과에 나타나길 원했을 수 있는 비즈니스 근처에 유사한 비즈니스가 얼마나 많을지, 그리고 그것들이 얼마나 유사하게 보일지 생각하게 합니다.
지역 검색에는 쿼리 로그에서 학습하는 유사한 지역 엔터티 하위 시스템이 있습니다.
Google 검색을 생각할 때 일반적으로 정보 검색 점수를 사용하여 검색자가 수행하는 쿼리에 대한 검색 결과의 관련성과 해당 결과에 대한 권위 점수를 결정하는 유기적 검색을 생각합니다. 이 특허는 로컬 결과가 처리될 때 유사한 로컬 엔터티 하위 시스템에 대해 설명합니다.
로컬 결과를 처리할 때 다른 로컬 엔티티에 대한 로컬 엔티티의 유사성은 로컬 엔티티를 참조하는 문서의 검색 점수를 결정할 때 사용될 수 있습니다. 마찬가지로, 검색 시스템이 문서와 독립적인 지역 개체를 검색하는 데 사용되는 경우(예: 레스토랑 검색), 다른 지역 개체에 대한 지역 개체의 유사성은 다음 항목에 대한 응답으로 나열할 지역 개체를 결정할 때도 사용할 수 있습니다. 로컬 엔터티 쿼리. 따라서, 검색 시스템은 로컬 엔티티 유사성 서브시스템을 포함하거나 로컬 엔티티 유사성 서브시스템과 데이터 통신할 수 있습니다. 로컬 엔티티 유사성 서브시스템은 각각의 로컬 엔티티에 대해, 목록이 대응하는 로컬 엔티티와의 유사성에 따라 순위가 매겨진 로컬 엔티티의 목록을 포함하는 유사한 로컬 엔티티의 대응하는 목록을 결정합니다.

로컬 엔터티 간의 유사성은 유사할 수 있는 특정 용어에 대한 쿼리 로그 결과에 비즈니스가 얼마나 자주 나타날 수 있는지에 대한 쿼리 로그 모양을 보고 부분적으로 결정할 수 있습니다.
프로세스는 로컬 엔티티 세트의 각 로컬 엔티티에 대해 쿼리 용어에 대한 용어 값 및 선택 값을 지정하는 데이터에 액세스합니다(202). 용어 값은 쿼리 로그에서 발생하는 쿼리 용어를 포함하는 쿼리의 여러 인스턴스에 비례합니다. 예를 들어, "Restaurant NYC Italian" 및 "Italian Restaurants Manhattan" 쿼리가 쿼리 로그에 각각 N번 나타난다고 가정합니다. 이 두 쿼리와 각각의 인스턴스를 기반으로 "레스토랑"에 대한 용어 값은 2N에 비례하는 반면, 'NYC', "이탈리아" 및 "맨해튼"에 대한 용어 값은 N에 비례합니다.
유사한 쿼리에 대한 응답으로 엔티티를 언급하는 특정 페이지를 선택하면 지역 검색에서 유사한 비즈니스를 결정하는 데 도움이 될 수 있습니까? 이는 해당 엔터티가 해당 페이지에서 얼마나 중요한지에 따라 달라질 수 있습니다. 특허는 다음과 같은 상황을 설명하는 것 같습니다.
선택 값은 각각이 쿼리 용어를 포함하고 쿼리 용어에 기인한 쿼리에 대한 응답으로 로컬 엔터티를 지정하는 검색 결과의 많은 선택에 비례합니다. 예를 들어, 각각 문서를 참조하는 검색 결과가 검색 쿼리에 대한 응답으로 제공된다고 가정합니다. 로컬 엔터티를 참조하는 문서를 참조하는 검색 결과의 각 선택에 대해 쿼리의 쿼리 용어에 대한 선택 값은 해당 로컬 엔터티에 대해 증가합니다. 선택 값이 얼마나 증가되는지는 일부 구현에서 엔티티가 문서의 주제에 얼마나 중요한지를 설명하는 점수에 따라 달라질 수 있습니다. 예를 들어, 위에서 설명한 수백 개의 레스토랑을 나열하고 각 레스토랑 엔터티에 대해 상대적으로 낮은 점수를 갖는 첫 번째 문서의 경우 특정 쿼리 용어 및 지역 엔터티에 대한 쿼리 용어 선택 값은 선택에 대한 응답으로 거의 증가하지 않습니다. 문서를 참조하는 검색 결과입니다. 반대로, 로컬 엔터티에 대해 높은 점수를 받은 두 번째 문서의 경우 특정 쿼리 용어 및 로컬 엔터티에 대한 쿼리 용어 선택 값은 첫 번째 로컬 문서 선택보다 훨씬 더 많이 증가합니다.
유사한 지역 단체의 거리는 사업 유형에 따라 중요도가 다를 수 있음
관련된 비즈니스 유형에 따라 유사한 지역 엔터티가 표시될 수 있습니다. 피자 가게까지 차로 얼마나 가겠습니까? 주유소를 위해?
이 특허는 다음과 같은 질문도 던집니다.
로컬 엔티티의 세트로부터 제2 로컬 엔티티의 적절한 서브세트를 선택하는 것은 예를 들어 제1 로컬 엔티티의 지리적 위치의 임계 거리 내에 지리적 위치를 갖는 로컬 엔티티를 선택하는 것을 포함할 수 있습니다. 임계값 거리는 고정된 거리이거나 로컬 엔티티 유형에 따라 다를 수 있습니다. 예를 들어, 레스토랑 유형의 첫 번째 엔터티의 경우 거리는 10마일일 수 있습니다. 주유소 유형의 첫 번째 엔티티의 경우 거리는 3마일일 수 있습니다. 등.
또한 이러한 거리에 대한 몇 가지 답변을 제공합니다.
거리는 또한 예상 이동 시간을 기반으로 할 수 있습니다. 예를 들어, 첫 번째 지역 개체가 선택되면 예상 운전 20분 이내의 다른 모든 지역 개체가 선택될 수 있습니다. 따라서, 지리적 경계(예: 다리, 강 등)에 따라 다른 지역 개체가 선택되는 영역이 단순히 원형이나 직사각형이 아닌 비대칭일 수 있습니다. 시간 기반 거리는 예를 들어 하위 집합 선택 단계 및 경로 찾기 알고리즘 외부의 시스템에서 얻은 트래픽 패턴에서 결정할 수 있습니다.
유사성을 결정하는 데 사용되는 쿼리 용어는 품질이 높고 품질이 낮을 수 있으며 클릭 선택 수를 확인합니다.
다른 장소에서 찾을 수 있는 검색어를 비교할 때 이러한 용어 중 일부는 "음식"과 같은 범주를 나타내는 용어와 같이 고품질 용어로 간주됩니다. 위치 용어 또는 탐색 용어와 같은 일부 검색어는 품질이 낮은 것으로 간주될 수 있습니다.
"NYC"와 같은 검색어에 사용된 위치 용어는 "pizza NYC" 또는 "Chinese Food NYC"와 같은 검색어에 나타날 수 있지만 이것이 "pizza"와 같은 용어가 레스토랑을 나타내는 방식의 유사성을 나타내지는 않습니다. 특히 피자를 제공합니다. "Lombardi's"와 같이 동네 이름이나 쇼핑 센터 이름과 같이 탐색 용어로 사용할 수 있는 쿼리 용어입니다. 같은 쇼핑 센터나 이웃에 있는 지역 엔터티는 매우 유사하지 않을 수 있습니다. 비교를 위해 쿼리 로그에 이러한 쿼리 용어가 있으면 품질이 낮은 용어보다 품질이 높은 용어에 더 도움이 될 수 있습니다. "해산물"로 확인된 두 곳은 "NYC"로 검색된 두 곳보다 더 유사할 수 있습니다.
이 특허는 쿼리 용어의 품질과 위치 또는 탐색 편향을 나타내는 용어 대 범주 용어에 대해 훨씬 더 깊이 있게 설명합니다. 지역 엔터티의 유사성을 나타내는 검색어 유형으로 범주를 선호하는 것 같습니다.
그러나 특히 해당 용어에 대한 선택이 유사한 경우 고품질 및 저품질 쿼리 용어 모두에 주의를 기울일 수 있습니다.
상대적 선택 값의 "유사성"은 쿼리 용어에 대한 선택 분포가 유사함을 의미합니다. 예를 들어 첫 번째 엔터티가 레스토랑이고 두 번째 엔터티가 카지노라고 가정합니다. 두 엔터티 모두 "레스토랑"이라는 용어가 포함된 쿼리에서 5,000회의 클릭이 있을 수 있지만 레스토랑 엔터티는 모든 쿼리에서 7,000건의 클릭이 발생한 반면 카지노는 모든 쿼리에서 1,000,000건의 클릭이 기여했습니다. 상대적 분포가 매우 다르기 때문에 이 두 엔티티에 대한 "레스토랑" 용어에 기인한 유사성은 거의 없습니다. 반대로 "레스토랑"이라는 검색어에서 4,000회의 클릭이 있는 다른 엔터티, 총 6,000건의 클릭은 "레스토랑"이라는 용어의 레스토랑 엔터티와 유사한 것으로 간주됩니다. 마찬가지로 "레스토랑"이라는 용어가 포함된 쿼리에서 6,000번의 클릭이 있고 총 975,000번의 클릭이 있는 또 다른 엔터티는 "레스토랑"이라는 용어에 대한 카지노 엔터티와 유사한 것으로 간주됩니다.
모든 쿼리 유형에서 선택 항목을 사용하면 서로 다른 두 위치가 서로 비슷하거나 매우 다를 수 있는지 여부를 나타낼 수 있습니다. 이는 클릭연결 정보를 사용하여 엔터티의 순위를 매기는 방법을 결정하는 것이 아니라 두 개의 로컬 엔터티가 유사한지 여부를 표시할지 여부를 결정하기 위한 것입니다.