
Como o Google pode determinar entidades locais semelhantes
Publicados: 2018-01-30
A pesquisa local é preenchida com entidades locais com significado local
A Pesquisa local do Google é mais baseada na semântica do que na pesquisa orgânica; onde as empresas são frequentemente chamadas de "entidades locais", como em uma patente concedida ao Google em 2 de janeiro de 2018. É mais uma consideração de coisas diferentes (como em "Coisas e não cadeias de caracteres"), em vez de correspondência palavras-chave nas páginas. Em parte, é por isso que vemos painéis de conhecimento para empresas hoje em dia no Google, depois que eles introduziram seu Mapa de conhecimento, que mostra entidades. Sua definição de entidade local, segundo essa patente, é interessante:
Alguns sistemas de pesquisa podem obter ou inferir a localização de um dispositivo de usuário do qual uma consulta de pesquisa foi recebida e incluir resultados de pesquisa locais que respondem à consulta de pesquisa. Um resultado de pesquisa local é um resultado de pesquisa que faz referência a um documento que descreve uma entidade local. Uma entidade local, por sua vez, é uma entidade que foi classificada como tendo importância local para um determinado local. As entidades locais são normalmente entidades físicas associadas a um endereço ou região, como um restaurante, um hospital, um ponto de referência e semelhantes. Um resultado de pesquisa que faz referência a um documento que descreve uma entidade local recebe um "impulso" de pontuação de pesquisa para uma consulta se o local associado à entidade local for próximo ao local do dispositivo do usuário. Por exemplo, em resposta a uma consulta de pesquisa por “cafeteria”, o sistema de pesquisa pode fornecer resultados de pesquisa locais que fazem referência a páginas da web de cafeterias próximas à localização do dispositivo do usuário. Muitos usuários em várias regiões geográficas provavelmente ficarão satisfeitos em receber resultados locais de cafeterias em resposta à consulta de pesquisa "cafeteria" porque é provável que um usuário que envia a consulta "cafeteria" esteja interessado nos resultados de pesquisa de cafeterias que são locais para a localização do usuário.
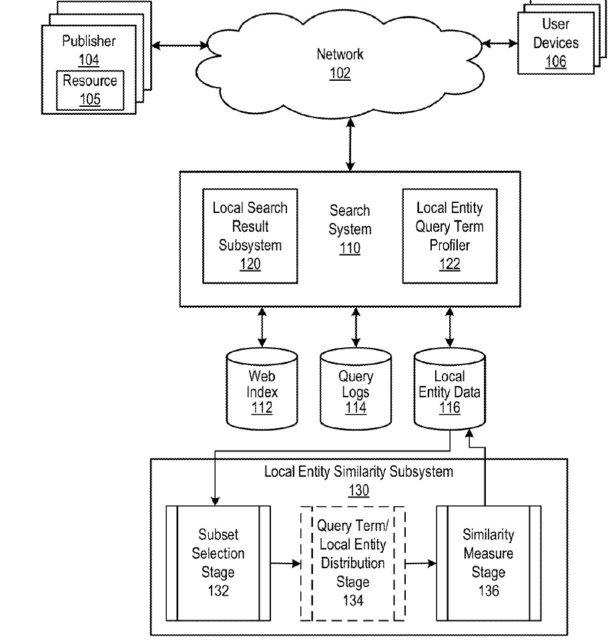
Exibir entidades locais semelhantes é uma meta
Esta nova patente não trata apenas de classificar entidades locais em resposta a uma consulta que seja relevante para essas entidades. Também nos diz que algumas pesquisas fornecerão resultados de pesquisa baseados na exibição de resultados semelhantes, o que também é interessante:
No contexto de entidades locais, por exemplo, os mecanismos de pesquisa podem fornecer resultados de pesquisa para entidades locais que estão relacionadas entre si de alguma forma predeterminada. Por exemplo, no contexto de restaurantes, sugestões para outros restaurantes que oferecem itens de menu semelhantes a preços semelhantes podem ser feitas em resposta a uma seleção de resultados de pesquisa que faz referência ao primeiro restaurante, ou em resposta a uma pesquisa de outros restaurantes relacionados a um primeiro restaurante.
Se procura um local para parar e tomar um café, sendo capaz de ver vários cafés por perto, mesmo alguns que possam estar mais distantes podem permitir decidir qual deseja visitar mesmo que um esteja mais perto e os outros estejam um pouco mais distante. A pergunta que eu tinha quando comecei a ler isto é o que o Google pode usar para decidir se diferentes entidades são semelhantes? Como eles determinaram isso? Como eles decidem se uma entidade local tem importância local para uma localização geográfica?
A patente nos diz que várias coisas fazem com que o processo nesta patente tenha aspectos inovadores. Esses incluem:
1) Dados de acesso especificando, para cada entidade local em um conjunto de entidades locais, em que cada entidade local é uma entidade física resolvida para uma localização geográfica e tendo significado local para a localização geográfica com base em termos de consulta que resolvem em seleções de entidades locais em uma localização.
2) Determinar uma medida de similaridade que é uma medida de similaridade de uma entidade local identificada e entidades locais similares; suas semelhanças podem ser suficientes para considerá-los parentes.
A patente é:
Detecção de entidades locais relacionadas
Inventores: Kumar Mayur Thakur e Mukund Jha
Cessionário: Google Inc.
Patente US 9.858.291
Concedido: 2 de janeiro de 2018
Arquivado: 30 de outubro de 2014
Resumo
Métodos, sistemas e aparelhos, incluindo programas de computador codificados em um meio de armazenamento de computador, para processar entidades locais. Em um aspecto, um método inclui acessar dados especificando termos de consulta para cada entidade local em um conjunto de entidades locais e para cada termo de consulta um valor de termo com base em muitas instâncias de consultas que incluem o termo de consulta ocorrendo em um registro de consulta e um valor de seleção com base em várias seleções de resultados de pesquisa em que cada um faz referência à entidade local em resposta a uma consulta que inclui o termo da consulta e atribuída ao termo da consulta; selecionar uma primeira entidade local do conjunto de entidades locais; selecionar um subconjunto de segundas entidades locais do conjunto de entidades locais; e para cada segunda entidade local no subconjunto, determinar uma medida de similaridade da segunda entidade local com a primeira entidade local.
Como são determinadas as semelhanças para entidades locais?
Os resultados locais no Google Maps são classificados com base em coisas como distância de um histórico de localização do celular, relevância do título de uma empresa para uma consulta procurando por ela e uma pontuação de destaque do local, com base em citações (e links e comentários podem contar como citações.) e uma pontuação de autoridade para um site de negócios.
Esta nova patente nos diz que o Google pode exibir sites semelhantes para acompanhar um resultado local específico, para dar a um pesquisador opções e escolhas de lugares para visitar. Ele explica como a similaridade é determinada, em termos de olhar para palavras que aparecem em consultas e descrições:
A medida de similaridade é baseada, em parte, nos dados do termo de consulta para cada entidade local. Um termo de consulta, conforme usado nesta descrição escrita, pode ser um n-grama que constitui parte de uma consulta, mas não precisa ser uma consulta inteira. Por exemplo, para a consulta “Restaurant Review Gino's”, os termos da consulta podem ser os unigramas “Restaurant”, “Review” e “Gino's”. Outros n-gramas, como bi-gramas, tri-gramas, etc., também podem ser usados como termos de consulta.
Além de procurar semelhanças de idioma, o Google também pode procurar entidades locais semelhantes em um raio de um determinado número de milhas. Isso me fez pensar em quantas empresas semelhantes podem estar próximas a uma empresa que eu gostaria que aparecesse nos resultados da pesquisa local e como essas empresas podem parecer semelhantes.
A pesquisa local tem um subsistema de entidade local semelhante que aprende com os registros de consulta
Quando pensamos em pesquisa no Google, normalmente pensamos em pesquisa orgânica, que usa pontuações de recuperação de informações para determinar a relevância dos resultados de pesquisa para uma consulta que um pesquisador realiza e pontuações de autoridade para esses resultados. Esta patente fala sobre um subsistema de entidade local semelhante para quando os resultados locais são processados:
Ao processar resultados locais, a semelhança de entidades locais com outras entidades locais pode ser usada ao determinar as pontuações de pesquisa de documentos que fazem referência às entidades locais. Da mesma forma, se o sistema de pesquisa for usado para pesquisar entidades locais independentes de documentos (por exemplo, como uma pesquisa de restaurantes), a semelhança de entidades locais com outras entidades locais também pode ser usada para determinar quais entidades locais listar em resposta a um consulta de entidade local. Consequentemente, o sistema de pesquisa pode incluir, ou estar em comunicação de dados com, um subsistema de similaridade de entidade local. O subsistema de similaridade de entidade local determina, para cada entidade local, uma lista correspondente de entidades locais semelhantes que inclui uma lista de entidades locais classificadas de acordo com sua similaridade com a entidade local à qual a lista corresponde.

As semelhanças entre entidades locais podem ser determinadas em parte observando as aparências do log de consulta de quantas vezes uma empresa pode aparecer nos resultados do log de consulta para certos termos que podem ser semelhantes:
O processo acessa dados especificando, para cada entidade local em um conjunto de entidades locais, valores de termo e valores de seleção para termos de consulta (202). O valor do termo é proporcional a várias instâncias de consultas que incluem o termo de consulta que ocorre em um log de consulta. Por exemplo, suponha que as consultas “Restaurantes italianos em NYC” e “Restaurantes italianos em Manhattan”, cada uma, respectivamente, apareçam N vezes em um log de consulta. Com base nessas duas consultas e suas respectivas instâncias, o valor do termo para “Restaurantes” é proporcional a 2N, enquanto os valores do termo para `NYC,” “Italiano” e “Manhattan” são proporcionais a N.
As seleções de certas páginas que mencionam entidades em resposta a consultas semelhantes podem ajudar a determinar quais empresas podem ser semelhantes em uma pesquisa local? Isso pode depender de quão importante essa entidade pode ser para aquela página. A patente parece descrever isso acontecendo:
O valor de seleção é proporcional a muitas seleções de resultados de pesquisa em que cada uma especifica, respectivamente, uma entidade local em resposta a uma consulta que inclui o termo da consulta e atribuída ao termo da consulta. Por exemplo, suponha que os resultados da pesquisa, cada um referenciando um documento, sejam fornecidos em resposta a uma consulta de pesquisa. Para cada seleção de um resultado de pesquisa que faz referência a um documento que, por sua vez, faz referência a uma entidade local, o valor de seleção para os termos da consulta da consulta é aumentado para essa entidade local. O quanto o valor de seleção é aumentado pode depender, em algumas implementações, da pontuação que descreve a importância da entidade para o objeto do documento. Por exemplo, para o primeiro documento que lista centenas de restaurantes, descritos acima, e tendo uma pontuação relativamente baixa para cada entidade de restaurante, um valor de seleção de termo de consulta para um termo de consulta específico e entidade local aumentaria muito pouco em resposta a uma seleção de um resultado de pesquisa que faz referência ao documento. Por outro lado, para o segundo documento que é altamente pontuado para a entidade local, um valor de seleção de termo de consulta para o termo de consulta específico e a entidade local seria aumentado muito mais do que para a seleção do primeiro documento local.
Distâncias de entidades locais semelhantes podem variar em importância com base no tipo de negócio
Entidades locais semelhantes podem ser mostradas com base no tipo de negócios envolvidos. A que distância você dirige até uma pizzaria? Para um posto de gasolina?
A patente também faz essas perguntas:
A seleção de um subconjunto adequado de segundas entidades locais do conjunto de entidades locais pode, por exemplo, envolver a seleção de entidades locais que têm uma localização geográfica dentro de um limite de distância da localização geográfica da primeira entidade local. A distância limite pode ser uma distância fixa ou pode variar com base no tipo de entidade local. Por exemplo, para a primeira entidade de um tipo de restaurante, a distância pode ser de 10 milhas; para a primeira entidade de um tipo de posto de gasolina, a distância pode ser de três milhas; etc.
Ele também fornece algumas respostas sobre essas distâncias:
A distância também pode ser baseada em um tempo estimado de viagem. Por exemplo, quando uma primeira entidade local é selecionada, todas as outras entidades locais dentro de uma viagem estimada de 20 minutos podem ser selecionadas. Assim, dependendo dos limites geográficos (por exemplo, pontes, rios, etc.), a área da qual outras entidades locais são selecionadas pode ser assimétrica, e não simplesmente circular ou retangular. A distância baseada no tempo pode ser determinada a partir de, por exemplo, padrões de tráfego obtidos de sistemas externos ao estágio de seleção de subconjunto e algoritmos de localização de caminhos.
Os termos de consulta usados para determinar a similaridade podem ser de alta e baixa qualidade e observe os números de seleção de clique
Ao comparar os termos de consulta para os quais diferentes locais podem ser encontrados, alguns desses termos são considerados termos de alta qualidade, como termos que indicam categorias, como “comida”. Alguns termos de consulta podem ser considerados de qualidade inferior, como termos de localização ou termos de navegação.
Um termo de local usado em uma consulta, como “NYC”, pode aparecer em consultas como “pizza NYC” ou “Chinese Food NYC”, mas isso não indica semelhanças com a forma como um termo como “pizza” indica um restaurante que serve especificamente pizza. Um termo de consulta que pode ser usado como termos de navegação, como o nome de um bairro ou o nome de um shopping center, como “Lombardi's”. Entidades locais no mesmo shopping center ou bairro podem não ser muito semelhantes. A presença desses termos de consulta em um log de consulta para comparação pode ser mais útil para os termos de qualidade superior do que para os de qualidade inferior. Dois lugares identificados como sendo encontrados para "frutos do mar" são possivelmente mais semelhantes do que dois locais encontrados para "Nova York".
A patente vai em muito mais profundidade sobre a qualidade dos termos de consulta e termos de categoria versus termos que indicam um local ou um viés de navegação. Eles parecem favorecer categorias como o tipo de termo de consulta que indica a semelhança de entidades locais.
Mas eles podem prestar atenção aos termos de consulta de alta e de baixa qualidade, especialmente quando as seleções para esses termos são semelhantes:
Uma “similaridade” de valores de seleção relativos significa que a distribuição das seleções para um termo de consulta é semelhante. Por exemplo, suponha que uma primeira entidade seja um restaurante e a segunda um cassino. Ambas as entidades podem ter 5.000 cliques de consultas com o termo “restaurante”, mas a entidade restaurante tem 7.000 cliques no total de todas as consultas atribuídas a ela, enquanto o cassino tem 1.000.000 de cliques no total de todas as consultas atribuídas a ela. Como as distribuições relativas são muito diferentes, há muito pouca semelhança atribuída ao termo “restaurante” para essas duas entidades. Por outro lado, em outra entidade com 4.000 cliques de consultas com o termo "restaurante", o total de 6.000 cliques seria considerado semelhante à entidade restaurante para o termo "restaurante". Da mesma forma, outra entidade com 6.000 cliques de consultas com o termo "restaurante" e 975.000 cliques no total seria considerada semelhante à entidade de cassino para o termo "restaurante".
Esse uso de seleções de todos os tipos de consulta pode indicar se dois lugares diferentes podem ser semelhantes ou muito diferentes um do outro. Isso não usa informações de clique para determinar como classificar entidades, mas para decidir se deve mostrar que duas entidades locais são semelhantes ou não.