
Comment Google peut déterminer des entités locales similaires
Publié: 2018-01-30
La recherche locale est remplie d'entités locales ayant une importance locale
La recherche locale de Google est plus basée sur la sémantique que sa recherche organique ; où les entreprises sont souvent appelées « entités locales », comme dans un brevet qui a été accordé à Google le 2 janvier 2018. mots-clés sur les pages. C'est en partie pourquoi nous voyons des panneaux de connaissances pour les entreprises ces jours-ci chez Google après avoir présenté leur Knowledge Graph, qui montre des entités. Leur définition d'une entité locale, sous ce brevet, est intéressante :
Certains systèmes de recherche peuvent obtenir ou déduire un emplacement d'un dispositif utilisateur à partir duquel une requête de recherche a été reçue et inclure des résultats de recherche locale qui répondent à la requête de recherche. Un résultat de recherche locale est un résultat de recherche qui fait référence à un document décrivant une entité locale. Une entité locale, à son tour, est une entité qui a été classée comme ayant une importance locale pour un emplacement particulier. Les entités locales sont typiquement des entités physiques associées à une adresse ou à une région, telles qu'un restaurant, un hôpital, un point de repère, etc. Un résultat de recherche référençant un document décrivant une entité locale reçoit un score de recherche « boost » pour une requête si l'emplacement associé à l'entité locale est proche de l'emplacement du dispositif utilisateur. Par exemple, en réponse à une requête de recherche pour « café », le système de recherche peut fournir des résultats de recherche locaux qui référencent des pages Web pour des cafés à proximité de l'emplacement du dispositif utilisateur. De nombreux utilisateurs dans diverses régions géographiques seront probablement satisfaits de recevoir des résultats locaux pour les cafés en réponse à la requête de recherche « coffee shop » car il est probable qu'un utilisateur soumettant la requête « coffee shop » soit intéressé par les résultats de recherche pour les cafés qui sont locaux à l'emplacement de l'utilisateur.
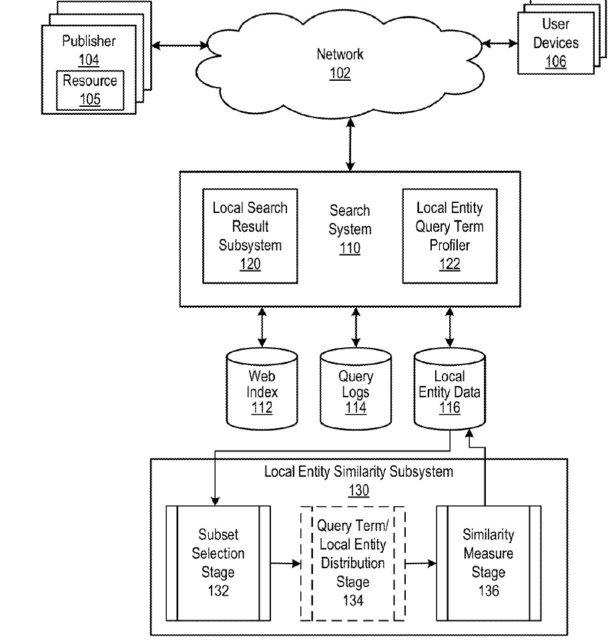
Afficher des entités locales similaires est un objectif
Ce nouveau brevet ne concerne pas seulement le classement des entités locales en réponse à une requête pertinente pour ces entités. Il nous indique également que certaines recherches fourniront des résultats de recherche basés sur des résultats similaires, ce qui est également intéressant :
Dans le contexte d'entités locales, par exemple, les moteurs de recherche peuvent fournir des résultats de recherche pour des entités locales qui sont liées les unes aux autres d'une manière prédéterminée. Par exemple, dans le contexte des restaurants, des suggestions pour d'autres restaurants qui proposent des éléments de menu similaires à des prix similaires peuvent être faites en réponse à une sélection de résultats de recherche faisant référence au premier restaurant, ou en réponse à une recherche d'autres restaurants liés à un premier resto.
Si vous cherchez un endroit où vous arrêter et prendre un café, pouvoir voir plusieurs cafés à proximité, même certains qui pourraient être plus éloignés, peut permettre de décider ce que vous voulez visiter même si l'un est plus proche et d'autres sont un peu plus éloigné. La question que je me posais lorsque j'ai commencé à lire ceci est de savoir ce que Google pourrait utiliser pour décider si différentes entités étaient similaires ? Comment ont-ils déterminé cela? Comment décident-ils si une entité locale a une importance locale pour un emplacement géographique ?
Le brevet nous dit que plusieurs choses font que le processus de ce brevet a des aspects innovants. Ceux-ci inclus:
1) Accéder aux données spécifiant, pour chaque entité locale dans un ensemble d'entités locales, où chaque entité locale est une entité physique résolue à un emplacement géographique et ayant une signification locale pour l'emplacement géographique sur la base de termes de requête qui se résolvent en sélections d'entités locales dans une location.
2) déterminer une mesure de similarité qui est une mesure de similarité d'une entité locale identifiée et d'entités locales similaires ; leurs similitudes peuvent suffire à les considérer comme apparentées.
Le brevet est :
Détection des entités locales liées
Inventeurs : Kumar Mayur Thakur et Mukund Jha
Cessionnaire : Google Inc.
Brevet américain 9 858 291
Accordé : 2 janvier 2018
Déposé : 30 octobre 2014
Résumé
L'invention concerne des procédés, des systèmes et un appareil, comprenant des programmes informatiques codés sur un support de stockage informatique, pour le traitement d'entités locales. Dans un aspect, un procédé comprend l'accès à des données spécifiant des termes de requête pour chaque entité locale dans un ensemble d'entités locales et pour chaque terme de requête une valeur de terme basée sur de nombreuses instances de requêtes qui incluent le terme de requête apparaissant dans un journal de requête, et une valeur de sélection sur la base de plusieurs sélections de résultats de recherche qui référencent chacune l'entité locale en réponse à une requête qui inclut le terme de requête et attribuée au terme de requête ; sélectionner une première entité locale dans l'ensemble des entités locales ; sélectionner un sous-ensemble de secondes entités locales à partir de l'ensemble d'entités locales ; et pour chaque seconde entité locale du sous-ensemble, déterminer une mesure de similarité de la seconde entité locale avec la première entité locale.
Comment les similitudes sont-elles déterminées pour les entités locales ?
Les résultats locaux dans Google Maps sont classés en fonction d'éléments tels que la distance par rapport à l'historique de localisation d'un mobile, la pertinence du titre d'une entreprise par rapport à une requête qui la recherche et un score d'importance de l'emplacement, basé sur des citations (et les liens et les critiques peuvent compter comme citations.) et un score d'autorité pour un site Web pour les entreprises.
Ce nouveau brevet nous dit que Google peut afficher des sites similaires pour accompagner un résultat local spécifique, pour donner au chercheur des options et des choix de lieux à visiter. Il explique comment la similarité est déterminée, en termes d'examen des mots qui apparaissent dans les requêtes et les descriptions :
La mesure de similarité est basée, en partie, sur les données de termes de requête pour chaque entité locale. Un terme de requête, tel qu'il est utilisé dans cette description écrite, peut être un n-gramme qui fait partie d'une requête, mais n'a pas besoin d'être une requête entière. Par exemple, pour la requête "Restaurant Review Gino's", les termes de la requête peuvent être les unigrammes "Restaurant", "Review" et "Gino's". D'autres n-grammes, tels que les bi-grammes, les tri-grammes, etc., peuvent également être utilisés comme termes de requête.
En plus de rechercher des similitudes linguistiques, Google peut également rechercher des entités locales similaires dans un rayon d'un certain nombre de kilomètres. Cela m'a fait penser au nombre d'entreprises similaires qui pourraient se trouver à proximité d'une entreprise que je souhaiterais voir apparaître dans les résultats de recherche locaux, et à quel point elles pourraient sembler similaires.
La recherche locale a un sous-système d'entité locale similaire qui apprend des journaux de requêtes
Lorsque nous pensons à la recherche sur Google, nous pensons généralement à la recherche organique qui utilise les scores de recherche d'informations pour déterminer la pertinence des résultats de la recherche par rapport à une requête effectuée par un chercheur et les scores d'autorité pour ces résultats. Ce brevet parle d'un sous-système d'entité locale similaire pour le traitement des résultats locaux :
Lors du traitement des résultats locaux, la similitude des entités locales avec d'autres entités locales peut être utilisée lors de la détermination des scores de recherche de documents faisant référence aux entités locales. De même, si le système de recherche est utilisé pour rechercher des entités locales indépendamment des documents (par exemple, une recherche de restaurants), la similitude des entités locales avec d'autres entités locales peut également être utilisée pour déterminer quelles entités locales répertorier en réponse à un requête d'entité locale. En conséquence, le système de recherche peut inclure, ou être en communication de données avec, un sous-système de similarité d'entité locale. Le sous-système de similarité d'entité locale détermine, pour chaque entité locale, une liste correspondante d'entités locales similaires qui comprend une liste d'entités locales classées en fonction de leur similarité avec l'entité locale à laquelle correspond la liste.

Les similitudes entre les entités locales peuvent être déterminées en partie en examinant les apparences du journal des requêtes sur la fréquence à laquelle une entreprise peut apparaître dans les résultats du journal des requêtes pour certains termes qui peuvent être similaires :
Le processus accède à des données spécifiant, pour chaque entité locale dans un ensemble d'entités locales, des valeurs de terme et des valeurs de sélection pour les termes de requête (202). La valeur du terme est proportionnelle à plusieurs instances de requêtes qui incluent le terme de requête apparaissant dans un journal de requête. Par exemple, supposons que les requêtes "Restaurants NYC Italian" et "Italian Restaurants Manhattan" apparaissent respectivement N fois dans un journal de requêtes. Sur la base de ces deux requêtes et de leurs instances respectives, la valeur du terme « Restaurants » est proportionnelle à 2N, tandis que les valeurs du terme « NYC », « Italien » et « Manhattan » sont proportionnelles à N.
Les sélections de certaines pages qui mentionnent des entités en réponse à des requêtes similaires peuvent-elles aider à déterminer quelles entreprises pourraient être similaires dans une recherche locale ? Cela peut dépendre de l'importance de cette entité pour cette page. Le brevet semble décrire ce qui se passe :
La valeur de sélection est proportionnelle à de nombreuses sélections de résultats de recherche qui spécifient chacune respectivement une entité locale en réponse à une requête qui inclut le terme de requête et attribuée au terme de requête. Par exemple, supposons que les résultats de la recherche, chacun référençant un document, soient fournis en réponse à une requête de recherche. Pour chaque sélection d'un résultat de recherche référençant un document qui, à son tour, référence une entité locale, la valeur de sélection pour les termes de requête de la requête est augmentée pour cette entité locale. L'augmentation de la valeur de sélection peut dépendre, dans certaines mises en œuvre, du score qui décrit l'importance de l'entité pour le sujet du document. Par exemple, pour le premier document qui répertorie des centaines de restaurants, décrit ci-dessus, et ayant un score relativement faible pour chaque entité de restaurant, une valeur de sélection de terme de requête pour un terme de requête particulier et une entité locale serait très peu augmentée en réponse à une sélection d'un résultat de recherche référençant le document. Inversement, pour le deuxième document qui est fortement noté pour l'entité locale, une valeur de sélection de terme de requête pour le terme de requête particulier et l'entité locale serait augmentée beaucoup plus que pour la sélection du premier document local.
Les distances d'entités locales similaires peuvent varier en importance en fonction du type d'entreprise
Des entités locales similaires peuvent être présentées en fonction du type d'entreprises concernées. Jusqu'où iriez-vous en voiture jusqu'à une pizzeria ? Pour une station essence ?
Le brevet pose également ces questions :
La sélection d'un sous-ensemble approprié de secondes entités locales à partir de l'ensemble d'entités locales peut, par exemple, impliquer la sélection d'entités locales qui ont un emplacement géographique à une distance seuil de l'emplacement géographique de la première entité locale. La distance seuil peut être une distance fixe ou peut varier en fonction du type d'entité locale. Par exemple, pour la première entité d'un type de restaurant, la distance peut être de 10 miles ; pour la première entité de type station-service, la distance peut être de trois milles ; etc.
Il fournit également quelques réponses concernant ces distances :
La distance peut également être basée sur une estimation du temps de trajet. Par exemple, lorsqu'une première entité locale est sélectionnée, toutes les autres entités locales à moins de 20 minutes de route estimées peuvent être sélectionnées. Ainsi, selon les limites géographiques (p. ex. ponts, rivières, etc.), la zone à partir de laquelle d'autres entités locales sont sélectionnées peut être asymétrique, et pas simplement circulaire ou rectangulaire. La distance basée sur le temps peut être déterminée à partir, par exemple, de modèles de trafic obtenus à partir de systèmes externes à l'étape de sélection de sous-ensemble et d'algorithmes de recherche de chemin.
Les termes de requête utilisés pour déterminer la similarité peuvent être de haute et de faible qualité et examinez les numéros de sélection de clic
Lors de la comparaison des termes de requête pour lesquels différents endroits peuvent être trouvés, certains de ces termes sont considérés comme des termes de haute qualité, tels que les termes qui indiquent des catégories, telles que « nourriture ». Certains termes de requête peuvent être considérés comme de moindre qualité, comme les termes de localisation ou les termes de navigation.
Un terme de lieu utilisé dans une requête, tel que "NYC" peut apparaître dans des requêtes telles que "pizza NYC" ou "Chinese Food NYC", mais cela n'indique pas des similitudes comme un terme tel que "pizza" indique un restaurant qui sert spécifiquement la pizza. Un terme de requête qui pourrait être utilisé comme termes de navigation, comme le nom d'un quartier ou le nom d'un centre commercial, comme « Lombardi's ». Les entités locales d'un même centre commercial ou d'un même quartier peuvent ne pas être très similaires. La présence de ces termes de requête dans un journal de requête à des fins de comparaison peut être plus utile pour les termes de qualité supérieure que pour ceux de qualité inférieure. Deux endroits identifiés comme étant trouvés pour « fruits de mer » sont peut-être plus similaires que deux endroits qui sont trouvés pour « NYC ».
Le brevet approfondit beaucoup plus la qualité des termes de requête et les termes de catégorie par rapport aux termes qui indiquent un emplacement ou un biais de navigation. Ils semblent privilégier les catégories comme type de terme de requête qui indique la similitude des entités locales.
Mais ils peuvent prêter attention aux termes de requête de haute qualité et de faible qualité, en particulier lorsque les sélections pour ces termes sont similaires :
Une « similitude » des valeurs de sélection relatives signifie que la distribution des sélections pour un terme de requête est similaire. Par exemple, supposons qu'une première entité est un restaurant et une seconde est un casino. Les deux entités peuvent avoir 5 000 clics à partir de requêtes avec le terme "restaurant", mais l'entité de restaurant a 7 000 clics au total pour toutes les requêtes qui lui sont attribuées, tandis que le casino a 1 000 000 de clics au total pour toutes les requêtes qui lui sont attribuées. Parce que les distributions relatives sont très différentes, il y a très peu de similitude attribuée au terme « restaurant » pour ces deux entités. À l'inverse, une autre entité avec 4 000 clics à partir de requêtes contenant le terme « restaurant », 6 000 clics au total seraient considérées comme similaires à l'entité de restaurant pour le terme « restaurant ». De même, une autre entité avec 6 000 clics à partir de requêtes contenant le terme « restaurant » et 975 000 clics au total serait considérée comme similaire à l'entité de casino pour le terme « restaurant ».
Cette utilisation de sélections de tous les types de requêtes peut indiquer si deux endroits différents peuvent être similaires ou très différents l'un de l'autre. Cela n'utilise pas les informations de clic pour déterminer comment classer les entités, mais plutôt pour décider s'il faut montrer que deux entités locales sont similaires ou non.