
ログファイル分析:SEOに使用できる9つの実用的な方法
公開: 2021-07-19この記事では、ログファイルとは何か、ログファイルが重要である理由、注意すべき点、使用するツールについて説明します。 最後に、SEOのためにそれらを分析できる9つの実用的な方法を紹介します。
サーバーログファイルとは何ですか?
サーバーログは、サーバーが実行したアクティビティのリストで構成されるサーバーによって自動的に作成および維持されるログファイル(または複数のファイル)です。
SEOの目的で、人間とロボットの両方からのWebサイトへのページ要求の履歴を含むWebサーバーログに関心があります。 これはアクセスログと呼ばれることもあり、生データは次のようになります。

はい、データは最初は少し圧倒されて混乱しているように見えるので、データを分解して「ヒット」をさらに詳しく見てみましょう。
ヒット例
すべてのサーバーは、ヒットのログ記録が本質的に異なりますが、通常、フィールドに編成された同様の情報を提供します。
以下は、Apache Webサーバーへのヒットのサンプルです(これは簡略化されています-一部のフィールドが削除されています)。
50.56.92.47 – – [01 / March / 2018:12:21:17 +0100]“ GET” –“ /wp-content/themes/esp/help.php” –“ 404”“-”“ Mozilla / 5.0(互換性; Googlebot / 2.1; + http://www.google.com/bot.html)」– www.example.com –
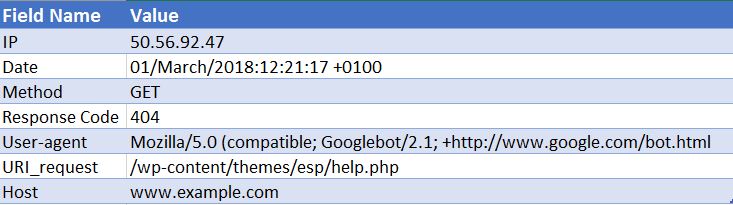
ご覧のとおり、ヒットごとに、日付と時刻、リクエストされたURIのレスポンスコード(この場合は404)、リクエストの送信元のユーザーエージェント(この場合はGooglebot)などの重要な情報が提供されます。 )。 ご想像のとおり、ログファイルは毎日数千のヒットで構成されています。ユーザーまたはボットがサイトにアクセスするたびに、画像、CSS、その他のレンダリングに必要なファイルなど、リクエストされたページごとに多くのヒットが記録されます。ページ。
なぜそれらは重要なのですか?
したがって、ログファイルとは何かを知っていますが、なぜそれらを分析する価値があるのでしょうか。
実のところ、Googlebotなどの検索エンジンがウェブサイトをどのように処理したかについての本当の記録は1つだけです。 そしてそれはあなたのウェブサイトのためにあなたのサーバーログファイルを見ることによるものです。
検索コンソール、サードパーティのクローラー、検索オペレーターは、Googlebotや他の検索エンジンがウェブサイトとどのように相互作用するかについての全体像を私たちに教えてくれません。 アクセスログファイルのみがこの情報を提供できます。
SEOにログファイル分析を使用するにはどうすればよいですか?
ログファイルの分析により、次のことができるようになるなど、非常に多くの有用な洞察が得られます。
- クロールできるものとできないものを正確に検証します。
- クロール中に検索エンジンが遭遇した応答を表示します(例:302、404、ソフト404)。
- より広範なサイトベースの影響(階層や内部リンク構造など)を伴う可能性のあるクロールの欠点を特定します。
- 検索エンジンが優先するページを確認し、最も重要と考える可能性があります。
- クロール予算の浪費の領域を発見します。
ログファイルの分析中に実行できるタスクのいくつかを紹介し、それらがWebサイトの実用的な洞察をどのように提供できるかを示します。
ログファイルを取得するにはどうすればよいですか?
このタイプの分析では、フィルタリングや変更を適用せずに、ドメインのすべてのWebサーバーからの生のアクセスログが必要です。 理想的には、分析を価値のあるものにするために大量のデータが必要になります。 これに相当する日/週の数は、サイトのサイズと権限、およびサイトが生成するトラフィックの量によって異なります。 一部のサイトでは1週間で十分な場合もあれば、1か月以上のデータが必要な場合もあります。
Web開発者は、これらのファイルを送信できるはずです。 ログに複数のドメインとプロトコルからのリクエストが含まれているかどうか、およびそれらがこのログに含まれているかどうかを送信する前に、彼らに尋ねる価値があります。 そうでない場合、これによりリクエストを正しく識別できなくなります。 http://www.example.com/とhttps://example.com/のリクエストを区別することはできません。 このような場合は、将来のためにこの情報を含めるためにログ構成を更新するように開発者に依頼する必要があります。
どのツールを使用する必要がありますか?
あなたがExcelの専門家なら、このガイドは、Excelを使用してログファイルをフォーマットおよび分析するのに非常に役立ちます。 個人的には、 Screaming Frog Log File Analyzerを使用しています(年間99ドルの費用がかかります)。 そのユーザーフレンドリーなインターフェイスにより、問題をすばやく簡単に見つけることができます(ただし、Excelを使用した場合と同じレベルの深さや自由度は得られません)。 ここで説明する例はすべて、Screaming Frog Log FileAnalyserを使用して実行されます。
他のいくつかのツールはSplunkとGamutLogViewerです。
SEOのログファイルを分析する9つの方法
1.クロール予算が無駄になっている場所を見つける
まず、クロール予算とは何ですか? Googleはそれを次のように定義しています:
「クロールレートとクロール需要を合わせて、クロールバジェットをGooglebotがクロールできるURLとクロールしたいURLの数として定義します。」
基本的に–これは、検索エンジンがサイトにアクセスするたびにクロールするページ数であり、ドメインの権限にリンクされており、Webサイトを介したリンクエクイティのフローに比例します。
重要なことに、ログファイルの分析に関連して、クロールの予算が無関係なページで無駄になることがあります。 インデックスに登録したい新しいコンテンツがあり、予算が残っていない場合、Googleはこの新しいコンテンツをインデックスに登録しません。 そのため、ログファイル分析を使用してクロール予算をどこで費やしているかを監視する必要があります。
クロール予算に影響を与える要因
付加価値の低いURLが多数あると、サイトのクロールとインデックス作成に悪影響を与える可能性があります。 低付加価値のURLは、次のカテゴリに分類できます。
- ファセットナビゲーション、動的URL生成、およびセッション識別子(eコマースWebサイトに共通)
- オンサイトの重複コンテンツ
- ハッキングされたページ
- ソフトエラーページ
- 低品質でスパムコンテンツ
このようなページでサーバーリソースを浪費すると、実際に価値のあるページからクロールアクティビティが消費され、サイトで適切なコンテンツを見つけるのに大幅な遅延が発生する可能性があります。
たとえば、これらのログファイルを見ると、間違ったWordPressテーマが頻繁にアクセスされていることがわかりました。これは、明らかな修正です。

各ページが取得しているイベントの数を確認するときは、 GoogleがこれらのURLをクロールする必要があるかどうかを自問してください。多くの場合、答えは「いいえ」です。 したがって、クロール予算を最適化すると、検索エンジンがWebサイトの最も重要なページをクロールしてインデックスに登録するのに役立ちます。 これは、 robots.txtファイルで特定のパターンを含むURLをブロックすることにより、クロールからURLを除外するなど、さまざまな方法で実行できます。 このテーマに関する役立つ投稿をご覧ください。
2.重要なページがクロールされていますか?
価値の低いページでクロールの予算を無駄にしないことがGoogleにとって重要である理由について説明しました。 コインの反対側は、あなたがそれらに置く重要性であなたの価値の高いページが訪問されていることを確認することです。 ログファイルをイベント数で並べ替え、HTMLでフィルタリングすると、最も訪問したページが何であるかを確認できます。
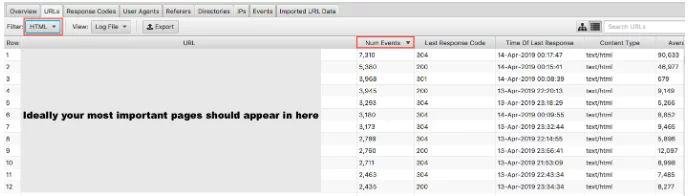
最も重要なURLを最もクロールする必要があると言うのは少し単純化されすぎますが、主要な世代のサイトの場合は、ホームページ、主要なサービスページ、ブログコンテンツをそこに表示する必要があります。
eコマースサイトとして、ホームページ、カテゴリページ、主要な製品ページをそこに表示する必要があります。 販売しなくなった古い商品ページが表示され、これらの結果で最も重要なカテゴリページがゼロになっている場合は、問題があります。
3.サイトがGoogleのモバイルファーストインデックスに切り替わったかどうかを確認します
ファイル分析をログに記録して、ウェブサイトがGooglebotスマートフォンによるクロールを増やしているかどうかを確認できます。これは、ウェブサイトがモバイルファーストインデックスに切り替えられたことを示します。 2019年7月1日の時点で、モバイルファーストインデックスはすべての新しいウェブサイトでデフォルトで有効になっています(ウェブが初めて、または以前はGoogle検索で不明でした)。 グーグル自身は次のように述べています。
「古いまたは既存のWebサイトについては、このガイドで詳しく説明されているベストプラクティスに基づいて、引き続きページを監視および評価します。 検索コンソールのサイト所有者に、サイトがモバイルファーストインデックスに切り替えられた日付を通知します。」 Googleモバイル-最初のインデックス作成のベストプラクティス
通常、まだ通常のインデックスに登録されているサイトでは、Googleのクロールの約80%がデスクトップクローラーによって実行され、20%がモバイルクローラーによって実行されます。 ほとんどの場合、モバイルファーストに切り替えられています。切り替えられている場合は、80/20の数値が逆になります。
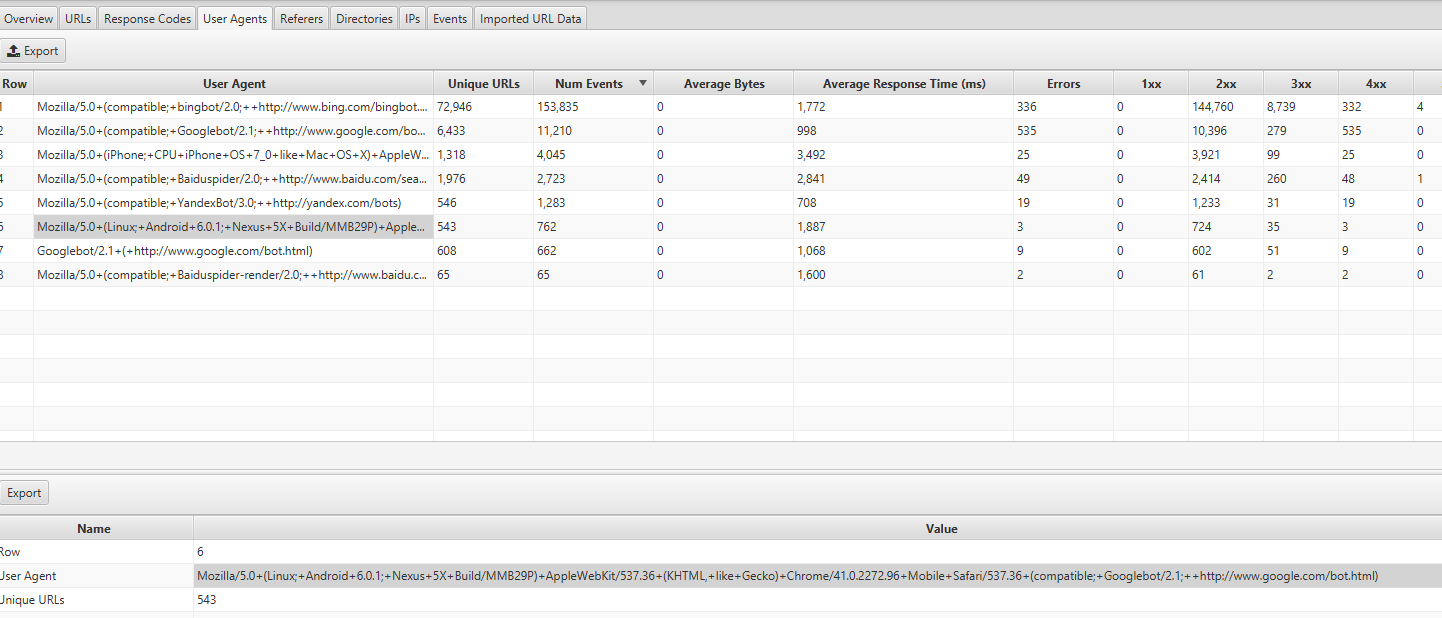
この情報は、Screaming Frog LogAnalyzerの[UserAgents]タブで確認できます。ほとんどのイベントは、Mozilla / 5.0(Linux、Android 6.0.1、Nexus 5X Build / MMB29P)AppleWebKit / 537.36(KHTML、 Geckoのように)Chrome / 41.0.2272.96 Mobile Safari / 537.36(互換; Googlebot / 2.1; + http://www.google.com/bot.html:
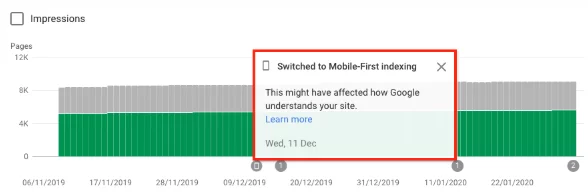
切り替えた場合は、ウェブサイトでモバイルファーストインデックスが有効になっているという通知もGoogle検索コンソールに表示されているはずです。 または、カバレッジレポートでもこれを確認できます。
4.ターゲットの検索エンジンボットはすべてページにアクセスしていますか?
ボットにこだわると、これは簡単に実行できるチェックです。 Googleが主要な検索エンジンであることを認識しているため、GooglebotスマートフォンとGooglebotが定期的にウェブサイトにアクセスしていることを確認することを優先する必要があります。
検索エンジンボットでログファイルデータをフィルタリングできます。
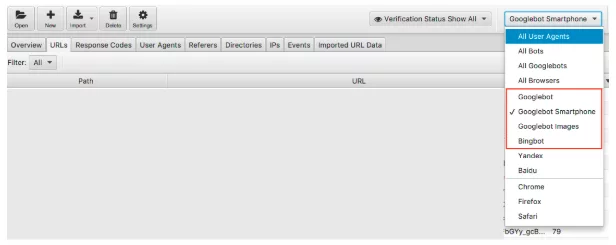
フィルタリングが完了すると、目的の各検索エンジンボットが記録しているイベントの数を確認できます。 うまくいけば、あなたはグーグルボットスマートフォンまたはグーグルボットがあなたのサイトを最も訪問しているのを見るでしょう。
また、不要なボットがどれだけWebサイトにアクセスしているかを確認することをお勧めします。 たとえば、ロシアや中国に商品やサービスを販売することを望まない英国の企業の場合、YandexボットとBaiduボットがサイトにどれだけアクセスしているかを確認できます。 彼らが異常な量を訪問している場合(私は彼らがGooglebotスマートフォンよりも多く訪問しているのを見たことがあります)、robots.txtでクローラーをブロックすることができます。
5.誤ったステータスコードの発見
Google検索コンソールのカバレッジレポートには404、有効な200に関する大量のデータがありますが、ログファイルには各ページのステータスコードの実際の概要が表示されます。 ログファイルまたはGoogle検索コンソールのフェッチとレンダリングを手動で送信することによってのみ、検索エンジンが経験した最後の応答コードを分析できます。
Screaming Frog Log File Analyserを使用すると、これをすばやく実行できます。また、クロール頻度順に並べられているため、修正する必要のある最も重要なURLを確認することもできます。
このデータを表示するには、[応答コード]タブでこの情報をフィルタリングできます
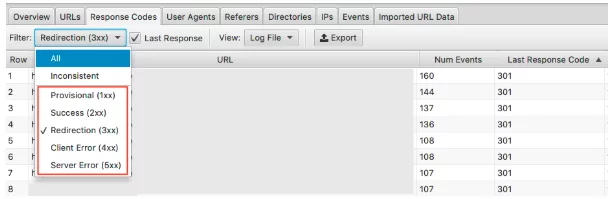
3xx、4xx、および5xxHTTPステータスのページを探します
- 彼らは頻繁に訪問されていますか?
- 3xx、4xx、5xxのページは、重要なページよりも多くアクセスされていますか?
- 応答コードにパターンはありますか?
1つのプロジェクトでは、ヒット数が最も多い上位15ページに、リダイレクト、誤った302(一時的)リダイレクト、コンテンツのないページ、および404とソフト404が含まれていました。

ログファイルの分析で、問題を特定したら、誤ったリダイレクトとソフト404を更新することで問題の修正を開始できます。
6.一貫性のない応答コードを強調表示する
検索エンジンが経験した最後の応答コードを分析することは重要ですが、一貫性のない応答コードを強調表示することで、優れた洞察を得ることができます。
最後の応答コードだけを見て、4xxsと5xxsに異常なエラーやスパイクが見られなかった場合は、そこでテクニカルチェックを完了することができます。 ただし、ログファイルアナライザーのフィルターを使用して、「一貫性のない」応答のみを詳細に表示できます。

URLで一貫性のない応答コードが発生する理由はたくさんあります。 例えば:
- 5xxと2xxの混合–これは、サーバーに深刻な負荷がかかっている場合にサーバーの問題を示している可能性があります。
- 4xxと2xxの混合–これは、表示または修正されたリンク切れを示している可能性があります
ログファイル分析からこの情報を入手したら、これらのエラーを修正するためのアクションプランを作成できます。
7.大きなページまたは遅いページを監査する
最初のバイトまでの時間(TTFB)、最後のバイトまでの時間(TTLB)、およびページ全体の読み込みまでの時間は、サイトのクロール方法に影響を与えます。 特にTTFBは、サイトを高速かつ効果的にクロールするための鍵です。 ページ速度もランキング要素であるため、高速Webサイトがパフォーマンスにとってどれほど重要であるかがわかります。
ログファイルを使用すると、Webサイトで最大のページと最も遅いページをすばやく確認できます。
最大のページを表示するには、「平均バイト数」列を並べ替えます。
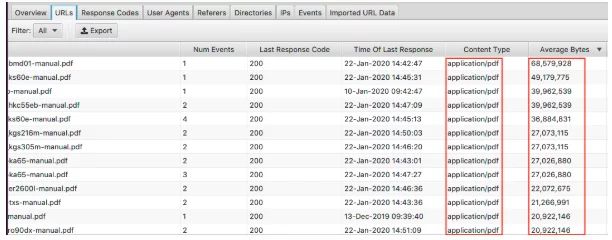
ここでは、PDFがWebサイトで最大のページを構成していることがわかります。 これらを最適化し、サイズを縮小することから始めるのが最適です。 ここに特定のページが表示されている場合は、それらを個別に確認することをお勧めします。
- 高解像度の画像で覆われていますか?
- 彼らは自動再生するビデオを持っていますか?
- 不要なカスタムフォントはありますか?
- テキスト圧縮は有効になっていますか?
ページのサイズは遅いページの良い指標ですが、それがすべてではありません。 あなたは大きなページを持つことができますが、それでも速くロードすることができます。 [平均応答時間]列を並べ替えると、応答時間が最も遅いURLが表示されます。
ここに表示されるすべてのデータと同様に、HTML、JavaScript、画像、CSSなどでフィルタリングできます。これは監査に非常に役立ちます。
おそらくあなたの目的は、あなたのウェブサイトのJavaScriptへの依存を減らし、最大の犯人を見つけたいということです。 または、CSSを合理化でき、バックアップするためのデータが必要なことをご存知でしょう。 サイトはカタツムリのペースで読み込まれる可能性があり、画像によるフィルタリングは、次世代フォーマットの提供を優先する必要があることを示しています。
8.内部リンクとクロール深度の重要性を確認します
このログファイルアナライザーのもう1つの優れた機能は、Webサイトのクロールをインポートする機能です。 これは非常に簡単で、ログファイルから分析できる内容にはるかに柔軟性があります。 クロールを下に表示されている「インポートされたURLデータ」にドラッグアンドドロップするだけです。
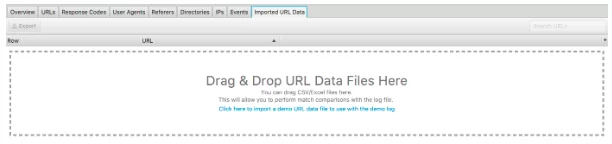
それが済んだら、さらに分析を行うことができます。
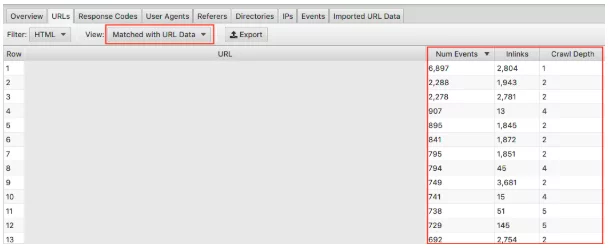
ドロップダウンで[URLデータと一致]を選択し、関連する列をビューにドラッグしてください。 ここでは、クロールの深さとリンクがWebサイトのクロール頻度に与える影響について一括分析を行うことができます。
たとえば、頻繁にクロールされない「重要な」ページがあり、それらのページにインリンクがほとんどなく、クロールの深さが3を超えている場合、これがページがあまりクロールされていない理由である可能性があります。 逆に、クロールされているページがたくさんあり、その理由がわからない場合は、サイトのどこにあるかを確認してください。 どこにリンクされていますか? 根からどれくらい離れていますか? これを分析することで、Googleがサイト構造について何を気に入っているかを知ることができます。 最終的に、この手法は、階層とサイト構造に関する問題を特定するのに役立ちます。
9.孤立したページを発見する
最後に、クロールデータがインポートされると、孤立したページを簡単に見つけることができます。 孤立したページは、検索エンジンが認識し、クロールしているが、Webサイトの内部にリンクされていないページとして定義できます。
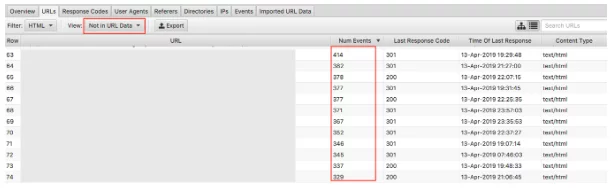
ドロップダウン「URLデータにありません」を選択すると、ログには存在するがクロールデータには存在しないURLが表示されます。 したがって、ここに表示されるURLは、検索エンジンボットがまだ価値があると考えているページになりますが、Webサイトには表示されなくなります。 孤立したURLは、次のような多くの理由で表示される可能性があります。
- サイト構造の変更
- コンテンツの更新
- 古いリダイレクトされたURL
- 不正な内部リンク
- 不正な外部リンク
最終的には、見つけた孤立したURLを確認し、それらをどうするかを判断する必要があります。
最終的な考え
これが、ログファイル分析とScreaming Frog Log FileAnalyserですぐに開始できる9つの実行可能なタスクの簡単な紹介です。 Excelと上記の他のツール(およびその他のツール)の両方で、できることはたくさんあります。 ここでカバーできる以上のものです! 以下は、私が役立つと思ったいくつかのリソースです。
ログファイル分析で答える7つの基本的な技術的なSEOの質問
ログファイル分析の究極のガイド
ログファイル分析の価値
そして、最も好奇心旺盛な技術的なSEO愛好家を満足させるはずの、読むべきものがもっとたくさんあります!
ログファイル分析をどのように実行しますか? どのツールが最も効果的だと思いますか? 私たちのSEOチームは知りたいです。 以下にコメントしてください。
何か新しいことを学んだばかりですか?
次に、毎月専門記事を読む80,000人の人々に加わってください。SEOについてサポートが必要な場合は、遠慮なくお問い合わせください。