
Анализ файла журнала: 9 действенных способов его использования для SEO
Опубликовано: 2021-07-19В этой статье мы расскажем, что такое файлы журналов, почему они важны, на что обращать внимание и какие инструменты использовать. Наконец, я дам 9 действенных способов их анализа для SEO.
Что такое файл журнала сервера?
Журнал сервера - это файл журнала (или несколько файлов), автоматически создаваемый и поддерживаемый сервером, состоящий из списка выполненных им действий.
В целях SEO нас интересует журнал веб-сервера, который содержит историю запросов страниц для веб-сайта как от людей, так и от роботов. Это также иногда называют журналом доступа, и необработанные данные выглядят примерно так:

Да, данные поначалу выглядят немного ошеломляющими и запутанными, поэтому давайте разберем их и посмотрим на «хит» более внимательно.
Пример попадания
Каждый сервер по своей сути отличается в регистрации обращений, но обычно они предоставляют схожую информацию, которая организована в поля.
Ниже приведен пример обращения к веб-серверу Apache (это упрощено - некоторые поля удалены):
50.56.92.47 - - [01 / March / 2018: 12: 21: 17 +0100] «GET» - «/wp-content/themes/esp/help.php» - «404» «-» «Mozilla / 5.0 ( совместимый; Googlebot / 2.1; + http: //www.google.com/bot.html) »- www.example.com -
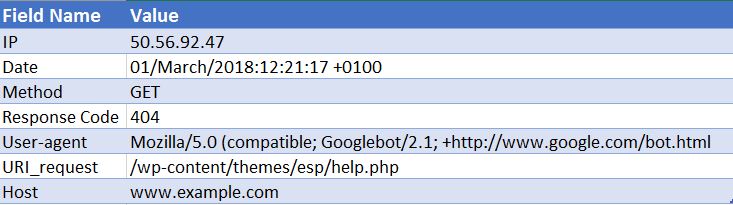
Как видите, для каждого обращения нам дается ключевая информация, такая как дата и время, код ответа запрошенного URI (в данном случае 404) и пользовательский агент, от которого поступил запрос (в данном случае робот Googlebot ). Как вы понимаете, файлы журнала состоят из тысяч обращений каждый день, поскольку каждый раз, когда пользователь или бот приходит на ваш сайт, для каждой запрошенной страницы записывается множество обращений, включая изображения, CSS и любые другие файлы, необходимые для отображения страница.
Почему они важны?
Итак, вы знаете, что такое файл журнала, но почему стоит потратить время на его анализ?
Дело в том, что существует только одна достоверная запись о том, как поисковые системы, такие как Googlebot, обрабатывают ваш сайт. И это можно сделать, просмотрев файлы журналов вашего сервера для вашего веб-сайта.
Консоль поиска, сторонние сканеры и операторы поиска не дадут нам полной картины того, как робот Googlebot и другие поисковые системы взаимодействуют с веб-сайтом. ТОЛЬКО файлы журнала доступа могут предоставить нам эту информацию.
Как мы можем использовать анализ файлов журнала для SEO?
Анализ файла журнала дает нам огромное количество полезных сведений, в том числе позволяет:
- Подтвердите, что именно можно сканировать, а что нельзя.
- Просмотрите ответы, полученные поисковыми системами во время сканирования, например 302-е, 404-е, мягкие 404-е.
- Выявите недостатки сканирования, которые могут иметь более широкое значение для сайта (например, иерархия или структура внутренних ссылок).
- Посмотрите, какие страницы поисковые системы отдают предпочтение и могут считать наиболее важными.
- Откройте для себя области растраты обходного бюджета.
Я расскажу вам о некоторых задачах, которые вы можете выполнить во время анализа файла журнала, и покажу, как они могут предоставить вам полезную информацию для вашего веб-сайта.
Как получить файлы журналов?
Для этого типа анализа вам потребуются необработанные журналы доступа со всех веб-серверов вашего домена без применения фильтрации или изменений. В идеале вам понадобится большой объем данных, чтобы анализ был целесообразным. Сколько это стоит дней / недель, зависит от размера и авторитета вашего сайта, а также от объема трафика, который он генерирует. Для некоторых сайтов может быть достаточно недели, для некоторых вам может потребоваться месяц или больше данных.
Ваш веб-разработчик должен иметь возможность отправлять вам эти файлы. Стоит спросить их, прежде чем они отправят вам, содержат ли журналы запросы из более чем одного домена и протокола и включены ли они в эти журналы. Потому что в противном случае это помешает вам правильно идентифицировать запросы. Вы не сможете отличить запрос http://www.example.com/ от https://example.com/. В этих случаях вам следует попросить вашего разработчика обновить конфигурацию журнала, чтобы включить эту информацию на будущее.
Какие инструменты мне нужно использовать?
Если вы специалист по Excel, то это руководство действительно поможет вам отформатировать и проанализировать файлы журналов с помощью Excel. Лично я использую анализатор файлов журнала Screaming Frog (стоимость 99 долларов в год). Его удобный интерфейс позволяет быстро и легко обнаруживать любые проблемы (хотя, возможно, вы не получите такой же уровень глубины и свободы, как при использовании Excel). Все примеры, которые я вам покажу, выполняются с использованием анализатора файлов журнала Screaming Frog.
Некоторые другие инструменты - Splunk и GamutLogViewer.
9 способов анализа файлов журналов для SEO
1. Найдите, на что тратится краулинговый бюджет.
Во-первых, что такое краулинговый бюджет? Google определяет это как:
«Взяв вместе скорость сканирования и потребность в сканировании, мы определяем бюджет сканирования как количество URL-адресов, которые робот Googlebot может и хочет просканировать».
По сути - это количество страниц, которые поисковая система будет сканировать каждый раз, когда она посещает ваш сайт, и оно связано с авторитетом домена и пропорционально потоку ссылок на веб-сайт.
Что особенно важно в отношении анализа файла журнала, иногда может тратиться бюджет сканирования на нерелевантные страницы. Если у вас есть свежий контент, который вы хотите проиндексировать, но у вас нет бюджета, Google не будет индексировать этот новый контент. Вот почему вы хотите отслеживать, на что вы тратите свой краулинговый бюджет, с помощью анализа файла журнала.
Факторы, влияющие на краулинговый бюджет
Наличие большого количества URL с низкой добавленной стоимостью может негативно повлиять на сканирование и индексирование сайта. URL-адреса с низкой добавленной стоимостью можно разделить на следующие категории:
- Фасетная навигация, динамическое создание URL-адресов и идентификаторы сеанса (общие для веб-сайтов электронной коммерции)
- Дублированный контент на сайте
- Взломанные страницы
- Страницы мягких ошибок
- Низкое качество и спам-контент
Потеря ресурсов сервера на таких страницах приведет к истощению активности сканирования со страниц, которые действительно имеют ценность, что может вызвать значительную задержку в обнаружении хорошего контента на сайте.
Например, просмотрев эти файлы журналов, мы обнаружили, что неправильная тема WordPress посещалась очень часто, это очевидное исправление!

Глядя на количество событий, которые получает каждая страница, спросите себя, следует ли Google сканировать эти URL-адреса - вы часто найдете ответ отрицательным. Таким образом, оптимизация бюджета сканирования поможет поисковым системам сканировать и индексировать самые важные страницы вашего сайта. Вы можете сделать это несколькими способами, например, исключить сканирование URL-адресов, заблокировав URL-адреса, содержащие определенные шаблоны, с помощью файла robots.txt . Прочтите наш полезный пост по этой теме.
2. Сканируются ли вообще ваши важные страницы?
Мы рассмотрели, почему для Google важно не тратить краулинговый бюджет на ваши малоценные страницы. Другая сторона медали - проверять, посещаются ли ваши ценные страницы с той важностью, которую вы им придаете. Если вы упорядочите файлы журналов по количеству событий и отфильтруете их по HTML, вы сможете увидеть, какие страницы вы посещаете чаще всего.
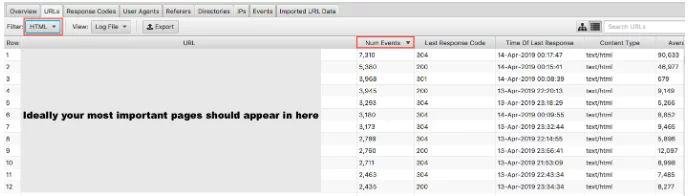
Было бы несколько упрощенно сказать, что ваши самые важные URL-адреса должны сканироваться больше всего - однако, если вы являетесь сайтом для генерации лидов, вы хотите, чтобы на нем отображались ваша домашняя страница, ключевые служебные страницы и контент блога.
Как сайт электронной коммерции, вы хотите, чтобы ваша домашняя страница, страницы категорий и ключевые страницы продуктов отображались там. Если вы видите старую страницу продукта, который больше не продаете, и ноль страниц с наиболее важными категориями в этих результатах, у вас проблема.
3. Узнайте, перешел ли ваш сайт на индекс Google, ориентированный на мобильные устройства.
Вы можете зарегистрировать анализ файла, чтобы узнать, получает ли ваш веб-сайт повышенное сканирование с помощью смартфона Googlebot, указывая, что он переключен на индекс , ориентированный на мобильные устройства . С 1 июля 2019 г. индексирование с ориентацией на мобильные устройства по умолчанию включено для всех новых веб-сайтов (новых в Интернете или ранее неизвестных для поиска Google). Сами Google заявили:
«Для старых или существующих веб-сайтов мы продолжаем отслеживать и оценивать страницы на основе передовых методов, подробно описанных в этом руководстве. Мы информируем владельцев сайтов в Search Console о дате, когда их сайт был переведен на индексирование с ориентацией на мобильные устройства ". Рекомендации по индексации Google Mobile-first
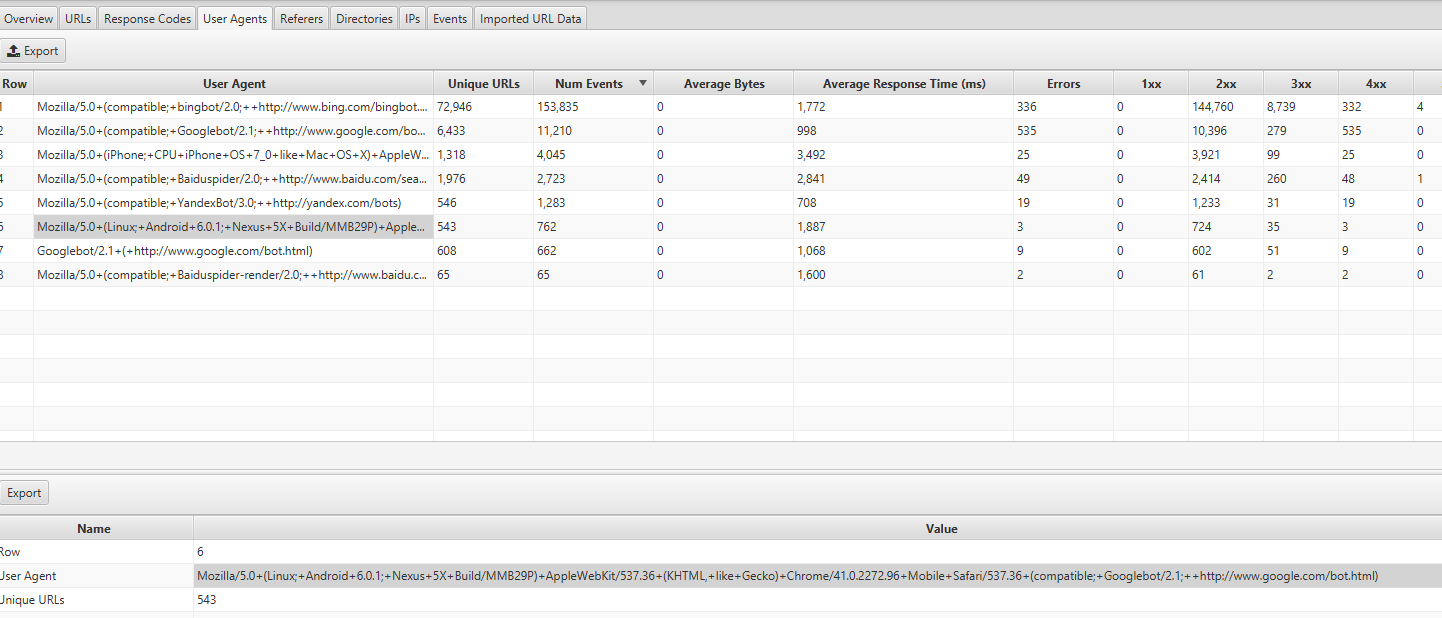
Обычно для сайта, который все еще находится в обычном индексе, около 80% сканирования Google выполняется поисковым роботом, а 20% - мобильным. Скорее всего, вы перешли на мобильные устройства, и если да, то числа 80/20 поменяются местами.
Вы можете найти эту информацию, просмотрев вкладку User Agents в Screaming Frog Log Analyzer - вы должны увидеть большинство событий, происходящих из Mozilla / 5.0 (Linux; Android 6.0.1; Nexus 5X Build / MMB29P) AppleWebKit / 537.36 (KHTML, как Gecko) Chrome / 41.0.2272.96 Mobile Safari / 537.36 (совместимый; Googlebot / 2.1; + http: //www.google.com/bot.html:
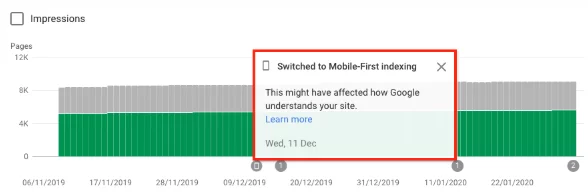
Если вас перевели, вы также должны были получить уведомление в Google Search Console о том, что на вашем веб-сайте включена индексация с ориентацией на мобильные устройства. Вы также можете увидеть это в отчете о покрытии.
4. Все ли целевые боты поисковых систем обращаются к вашим страницам?
Если придерживаться ботов, это несложная проверка. Мы знаем, что Google является доминирующей поисковой системой, и поэтому обеспечение регулярного посещения вашего веб-сайта роботами Googlebot Smartphone и Googlebot должно быть вашим приоритетом.
Мы можем фильтровать данные файла журнала с помощью робота поисковой системы.
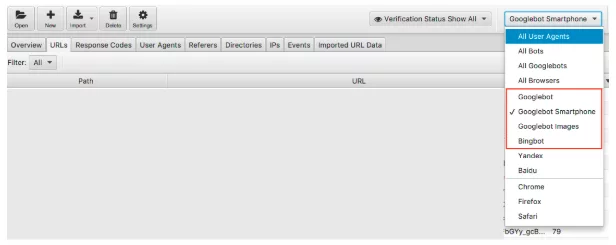
После фильтрации вы можете посмотреть, сколько событий записывает каждый из ваших поисковых роботов. Надеюсь, вы увидите, что робот Googlebot Smartphone или Googlebot чаще всего посещает ваш сайт.
Я также рекомендую проверить, сколько каждый нежелательный бот посещает ваш сайт. Например, если вы британский бизнес и не хотите продавать товары или услуги в Россию или Китай, вы можете узнать, сколько роботов Яндекс и Baidu посещают ваш сайт. Если они посещают необычное количество посетителей (я видел в некоторых случаях, что они посещают больше, чем смартфон Googlebot), вы можете заблокировать поисковые роботы в своем файле robots.txt.
5. Обнаружение неправильных кодов состояния
В то время как мы получаем тонну данных в отчете о покрытии консоли поиска Google о 404, действительных 200, файлы журналов дают нам фактический обзор кодов состояния каждой страницы. Только файлы журнала или ручная отправка выборки и рендеринга в Google Search Console могут позволить вам проанализировать последний код ответа, с которым будет работать поисковая система.

С помощью анализатора файлов журнала Screaming Frog вы можете сделать это быстро и, поскольку они упорядочены по частоте сканирования, вы также можете увидеть, какие URL-адреса потенциально являются наиболее важными для исправления.
Чтобы увидеть эти данные, вы можете отфильтровать эту информацию на вкладке «Коды ответов».
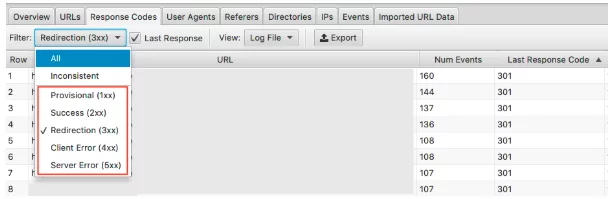
Ищите страницы с HTTP-статусами 3xx, 4xx и 5xx
- Их часто навещают?
- Страницы с 3xx, 4xx и 5xx посещаются чаще, чем ваши важные страницы?
- Есть ли закономерности в кодах ответов?
В одном проекте в топ-15 страниц с наибольшим количеством посещений были редиректы , неправильные 302 (временные) перенаправления, страницы без контента, а некоторые были 404-м и мягким 404-м .
После анализа файла журнала, как только вы определили проблему, вы можете приступить к ее устранению, обновив неправильные перенаправления и программные сообщения 404.
6. Выделите несовместимые коды ответов.
Хотя важно проанализировать последний код ответа, с которым будет работать поисковая система, выделение несовместимых кодов ответа также может дать вам хорошее представление.
Если вы посмотрели только на последние коды ответов и не увидели необычных ошибок или всплесков в 4xx и 5xx, вы можете завершить там свои технические проверки. Однако вы можете использовать фильтр в анализаторе файла журнала только для подробного просмотра «несогласованных» ответов.

Есть много причин, по которым ваши URL-адреса могут иметь несовместимые коды ответов. Например:
- 5xx смешано с 2xx - это может указывать на проблему с сервером, когда он находится под большой нагрузкой.
- 4xx смешанный с 2xx - это может указывать на появившиеся или исправленные неработающие ссылки.
Получив эту информацию из анализа файла журнала, вы можете составить план действий по исправлению этих ошибок.
7. Аудит больших или медленных страниц.
Мы знаем, что время до первого байта (TTFB), время до последнего байта (TTLB) и время до полной загрузки страницы влияют на то, как сканируется ваш сайт. TTFB, в частности, является ключом к быстрому и эффективному сканированию вашего сайта. Поскольку скорость страницы также является фактором ранжирования, мы можем видеть, насколько быстрый веб-сайт важен для вашей производительности.
Используя файлы журнала, мы можем быстро увидеть самые большие страницы вашего сайта и самые медленные.
Чтобы просмотреть самые большие страницы, отсортируйте столбец «Среднее количество байтов».
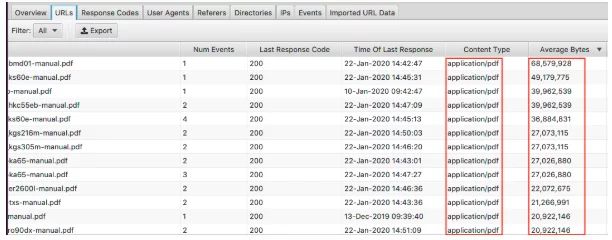
Здесь мы видим, что PDF-файлы составляют самые большие страницы на веб-сайте. Оптимизация и уменьшение их размера - отличное место для начала. Если вы видите, что здесь появляются определенные страницы, вы можете просмотреть их по отдельности.
- Покрыты ли они изображениями в высоком разрешении?
- У них есть автовоспроизведение видео?
- У них есть ненужные кастомные шрифты?
- Включено ли сжатие текста?
Хотя размер страницы является хорошим индикатором медленной страницы, это еще не все. У вас может быть большая страница, но она все равно может загружаться быстро. Отсортируйте столбец «Среднее время ответа», и вы увидите URL-адреса с самым медленным временем ответа.
Как и все данные, которые вы видите здесь, вы можете фильтровать по HTML, JavaScript, изображениям, CSS и т. Д., Что действительно полезно для вашего аудита.
Возможно, ваша цель - уменьшить зависимость вашего сайта от JavaScript и выявить главных виновников. Или вы знаете, что CSS можно оптимизировать, и вам нужны данные для его резервного копирования. Ваш сайт может загружаться со скоростью улитки, и фильтрация по изображениям демонстрирует вам, что обслуживание форматов следующего поколения должно быть приоритетом.
8. Проверьте внутренние ссылки и важность глубины сканирования.
Еще одна замечательная функция этого анализатора файлов журнала - это возможность импортировать сканирование веб-сайта. Это действительно просто сделать, и это дает вам гораздо больше гибкости в том, что вы можете анализировать из файлов журнала. Просто перетащите сканирование в поле «Импортированные данные URL», показанное ниже.
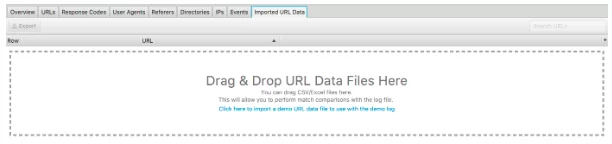
Как только вы это сделаете, вы можете провести дальнейший анализ.
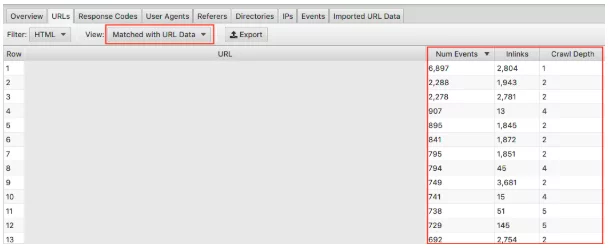
Убедитесь, что вы выбрали в раскрывающемся списке «Сопоставлено с данными URL» и перетащите соответствующие столбцы в представление. Здесь мы можем провести массовый анализ влияния глубины сканирования и входящих ссылок на частоту сканирования вашего веб-сайта.
Например, если у вас есть «важные» страницы, которые не сканируются часто, и вы заметили, что на них очень мало входящих ссылок, а глубина сканирования превышает 3, то, скорее всего, ваша страница сканируется не так часто. И наоборот, если у вас есть страница, которую много сканируют, и вы не знаете, почему, посмотрите, где она находится на вашем сайте. Где это связано? Насколько далеко это от рута? Анализ этого может указать вам, что Google нравится в структуре вашего сайта. В конечном итоге этот метод может помочь вам выявить любые проблемы с иерархией и структурой сайта.
9. Найдите потерянные страницы
Наконец, с импортированными данными сканирования легко обнаружить потерянные страницы. Сиротские страницы можно определить как страницы, о которых поисковые системы знают и сканируют, но не имеют внутренних ссылок на вашем веб-сайте.
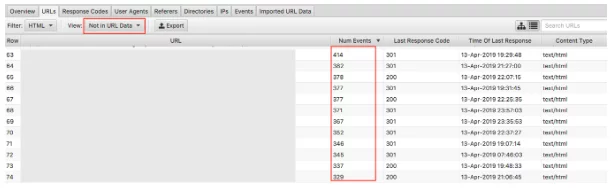
При выборе раскрывающегося списка «Не в данных URL» будут отображаться URL-адреса, которые присутствуют в журналах, но отсутствуют в ваших данных сканирования . Следовательно, URL-адреса, которые появляются здесь, будут страницами, которые, по мнению роботов поисковых систем, имеют ценность, но больше не отображаются на веб-сайте. Потерянные URL-адреса могут появляться по многим причинам, в том числе:
- Изменения в структуре сайта
- Обновления содержания
- Старые перенаправленные URL-адреса
- Неправильная внутренняя ссылка
- Неправильная внешняя ссылка
В конце концов, вам нужно просмотреть URL-адреса сирот, которые вы найдете, и решить, что с ними делать.
Последние мысли
Итак, это мое краткое введение в анализ файлов журнала и 9 практических задач, которые вы можете начать прямо сейчас с помощью анализатора файлов журнала Screaming Frog. Вы можете сделать гораздо больше как в Excel, так и с помощью других инструментов, упомянутых выше (а также других). Больше, чем я могу здесь рассказать! Ниже приведены некоторые полезные ресурсы:
7 фундаментальных технических вопросов SEO, на которые нужно ответить с помощью анализа файла журнала
Полное руководство по анализу файлов журнала
Значение анализа файла журнала
И есть еще масса, которую можно почитать, что должно удовлетворить самых любопытных технических энтузиастов SEO!
Как вы проводите анализ файла журнала? Какие инструменты вам подходят лучше всего? Наша команда SEO хотела бы знать. Комментарий ниже.
Вы только что узнали что-то новое?
Тогда присоединяйтесь к 80 000 человек, которые ежемесячно читают наши экспертные статьи.Если вам нужна помощь с вашим SEO, не стесняйтесь обращаться к нам.