
Analiza fișierelor jurnal: 9 moduri de acțiune care pot fi utilizate pentru SEO
Publicat: 2021-07-19În această piesă, vom acoperi ce sunt fișierele jurnal, de ce sunt semnificative, ce să căutăm și ce instrumente să folosim. În cele din urmă, voi oferi 9 moduri de acțiune prin care le puteți analiza pentru SEO.
Ce este un fișier jurnal server?
Un jurnal server este un fișier jurnal (sau mai multe fișiere) creat și întreținut automat de un server constând dintr-o listă de activități pe care le-a efectuat.
În scopuri SEO, ne preocupă un jurnal de server web care conține un istoric al solicitărilor de pagini pentru un site web, atât de la oameni, cât și de la roboți. Acest lucru este denumit uneori și un jurnal de acces, iar datele brute arată cam așa:

Da, datele arată un pic copleșitoare și confuze la început, așa că haideți să le descompunem și să privim o „lovitură” mai atentă.
Un exemplu de lovitură
Fiecare server este inerent diferit în accesările de jurnalizare, dar de obicei oferă informații similare care sunt organizate în câmpuri.
Mai jos este un exemplu de accesare la un server web Apache (acest lucru este simplificat - unele dintre câmpuri au fost scoase):
50.56.92.47 - - [01 / martie / 2018: 12: 21: 17 +0100] „GET” - „/wp-content/themes/esp/help.php” - „404” „-” „Mozilla / 5.0 ( compatibil; Googlebot / 2.1; + http: //www.google.com/bot.html) ”- www.example.com -
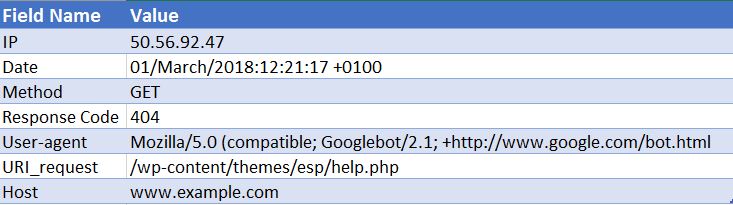
După cum puteți vedea, pentru fiecare accesare ni se oferă informații cheie, cum ar fi data și ora, codul de răspuns al URI-ului solicitat (în acest caz, un 404) și agentul utilizator de la care a venit solicitarea (în acest caz Googlebot ). După cum vă puteți imagina, fișierele jurnal sunt alcătuite din mii de accesări în fiecare zi, deoarece de fiecare dată când un utilizator sau bot ajunge la site-ul dvs., sunt înregistrate multe accesări pentru fiecare pagină solicitată - inclusiv imagini, CSS și orice alte fișiere necesare pentru a reda pagină.
De ce sunt semnificative?
Deci, știți ce este un fișier jurnal, dar de ce merită timpul dvs. să le analizați?
Ei bine, adevărul este că există o singură înregistrare adevărată a modului în care motoarele de căutare, precum Googlebot, procesează site-ul dvs. web. Și asta se referă la fișierele jurnal ale serverului pentru site-ul dvs. web.
Search Console, crawlerele terțe și operatorii de căutare nu ne vor oferi imaginea completă a modului în care Googlebot și alte motoare de căutare interacționează cu un site web. DOAR fișierele jurnal de acces ne pot oferi aceste informații.
Cum putem folosi analiza fișierelor jurnal pentru SEO?
Analiza fișierelor jurnal ne oferă o sumă imensă de informații utile, inclusiv permițându-ne să:
- Validați exact ceea ce poate sau nu poate fi accesat cu crawlere.
- Vizualizați răspunsurile întâlnite de motoarele de căutare în timpul accesării cu crawlere, de exemplu 302s, 404s, soft 404s.
- Identificați deficiențele de accesare cu crawlere, care ar putea avea implicații mai largi pe site-uri (cum ar fi ierarhia sau structura internă a legăturilor).
- Vedeți ce pagini acordă prioritate motoarelor de căutare și care ar putea fi considerate cele mai importante.
- Descoperiți zonele cu deșeuri bugetare.
Vă voi parcurge câteva dintre sarcinile pe care le puteți efectua în timpul analizei fișierului jurnal și vă voi arăta cum vă pot oferi informații utile pentru site-ul dvs. web.
Cum pot obține fișierele jurnal?
Pentru acest tip de analiză, aveți nevoie de jurnalele de acces brute de la toate serverele web pentru domeniul dvs., fără filtrare sau modificări aplicate. În mod ideal, veți avea nevoie de o cantitate mare de date pentru ca analiza să merite. Câte zile / săptămâni merită acest lucru, depinde de mărimea și autoritatea site-ului dvs. și de cantitatea de trafic pe care o generează. Pentru unele site-uri ar putea fi suficientă o săptămână, pentru unele site-uri este posibil să aveți nevoie de o lună sau mai mult de date.
Dezvoltatorul dvs. web ar trebui să vă poată trimite aceste fișiere. Merită să îi întrebați înainte să vă trimită dacă jurnalele conțin cereri de la mai mult de un singur domeniu și protocol și dacă sunt incluse în aceste jurnale. Pentru că dacă nu, acest lucru vă va împiedica să identificați corect solicitările. Nu veți putea face diferența dintre o solicitare pentru http://www.example.com/ și https://example.com/. În aceste cazuri, ar trebui să solicitați dezvoltatorului dvs. să actualizeze configurația jurnalului pentru a include aceste informații pentru viitor.
Ce instrumente trebuie să folosesc?
Dacă sunteți un expert în Excel, atunci acest ghid este foarte util pentru a vă ajuta să formatați și să analizați fișierele jurnal folosind Excel. Personal, folosesc Screaming Frog Log File Analyzer (costă 99 USD pe an). Interfața sa ușor de utilizat face rapidă și ușoară depistarea oricăror probleme (deși, fără îndoială, nu veți obține același nivel de adâncime sau libertate pe care l-ați câștiga folosind Excel). Exemplele pe care le voi trece sunt făcute folosind Screaming Frog Log File Analyzer.
Alte instrumente sunt Splunk și GamutLogViewer.
9 moduri de a analiza fișierele jurnal pentru SEO
1. Găsiți unde se risipește bugetul cu crawlere
În primul rând, ce este bugetul de accesare cu crawlere? Google îl definește ca:
„Luând împreună rata de accesare cu crawlere și cererea de accesare cu crawlere, definim bugetul de accesare cu crawlere ca număr de adrese URL pe care Googlebot le poate și vrea să le acceseze cu crawlere.
În esență - este numărul de pagini pe care un motor de căutare le va accesa cu crawlere de fiecare dată când accesează site-ul dvs. și este legat de autoritatea unui domeniu și proporțional cu fluxul de echitate al link-ului printr-un site web.
În mod crucial în ceea ce privește analiza fișierelor jurnal, bugetul cu accesarea cu crawlere poate fi uneori irosit pe pagini irelevante. Dacă aveți conținut proaspăt pe care doriți să îl indexați, dar nu mai aveți buget, atunci Google nu va indexa acest nou conținut. De aceea, doriți să monitorizați unde vă cheltuiți bugetul de accesare cu crawlere cu analiza fișierului jurnal.
Factorii care afectează bugetul de accesare cu crawlere
Dacă aveți multe adrese URL cu valoare adăugată redusă, acestea pot afecta negativ accesarea cu crawlere și indexarea site-ului. Adresele URL cu valoare redusă pot fi încadrate în următoarele categorii:
- Navigare cu fațete, generare URL dinamică și identificatori de sesiune (comun pentru site-urile de comerț electronic)
- Conținut duplicat la fața locului
- Pagini piratate
- Pagini de eroare ușoare
- Conținut de calitate scăzută și spam
Pierderea resurselor serverului pe pagini ca acestea va scurge activitatea de accesare cu crawlere din paginile care au de fapt valoare, ceea ce poate provoca o întârziere semnificativă în descoperirea conținutului bun pe un site.
De exemplu, uitându-ne la aceste fișiere jurnal, am descoperit că o temă WordPress incorectă a fost vizitată foarte frecvent, aceasta este o soluție evidentă!

Când vă uitați la numărul de evenimente pe care le primește fiecare pagină, întrebați-vă dacă Google ar trebui să se deranjeze cu accesarea cu crawlere a acestor adrese URL - Veți găsi adesea că răspunsul este negativ. Prin urmare, optimizarea bugetului de accesare cu crawlere va ajuta motoarele de căutare să acceseze cu crawlere și indexarea celor mai importante pagini de pe site-ul dvs. web. Puteți face acest lucru în mai multe moduri, cum ar fi excluderea URL-urilor de la accesarea cu crawlere prin blocarea adreselor URL care conțin anumite modele cu fișierul robots.txt . Consultați postarea noastră utilă pe această temă.
2. Paginile dvs. importante sunt cu crawlere?
Am analizat de ce este important ca Google să nu irosească bugetul pentru accesarea cu crawlere pe paginile dvs. cu valoare redusă. Cealaltă față a monedei este să verificați dacă paginile dvs. de mare valoare sunt vizitate cu importanța pe care o acordați asupra lor. Dacă comandați fișierele jurnal după numărul de evenimente și filtrați după HTML, puteți vedea care sunt cele mai vizitate pagini.
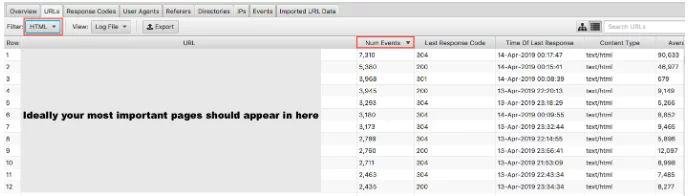
Ar fi oarecum simplificat să spunem că cele mai importante adrese URL ar trebui să fie crawlere cel mai mult - totuși, dacă sunteți un site principal, doriți ca pagina dvs. de pornire, paginile de servicii cheie și conținutul blogului să apară acolo.
Ca site de comerț electronic, ați dori ca pagina dvs. de pornire, paginile categoriei și paginile cheie ale produsului să apară acolo. Dacă vedeți o pagină de produs veche pe care nu o mai vindeți și zero dintre cele mai importante pagini din categoria dvs. în aceste rezultate, aveți o problemă.
3. Aflați dacă site-ul dvs. a trecut la indexul Google Mobile-First
Puteți înregistra analiza fișierelor pentru a afla dacă site-ul dvs. web primește accesarea cu crawlere sporită de Googlebot Smartphone, indicând faptul că acesta a fost trecut la indexul primul mobil . Începând cu 1 iulie 2019, indexarea pe primul dispozitiv mobil este activată în mod prestabilit pentru toate site-urile web noi (noi pe web sau necunoscute anterior pentru Căutarea Google). Google însuși a declarat:
„Pentru site-urile web mai vechi sau existente, continuăm să monitorizăm și să evaluăm paginile pe baza celor mai bune practici detaliate în acest ghid. Informăm proprietarii de site-uri în Search Console despre data când site-ul lor a fost trecut la indexarea pe primul dispozitiv mobil. ” Cele mai bune practici de indexare pentru Google Mobile
De obicei, un site care se află încă în indexul obișnuit va avea aproximativ 80% din crawling-ul Google realizat de crawler-ul desktop și 20% de cel mobil. Cel mai probabil ați fost trecut pe primul dispozitiv mobil și, dacă aveți, acele numere 80/20 se vor inversa.
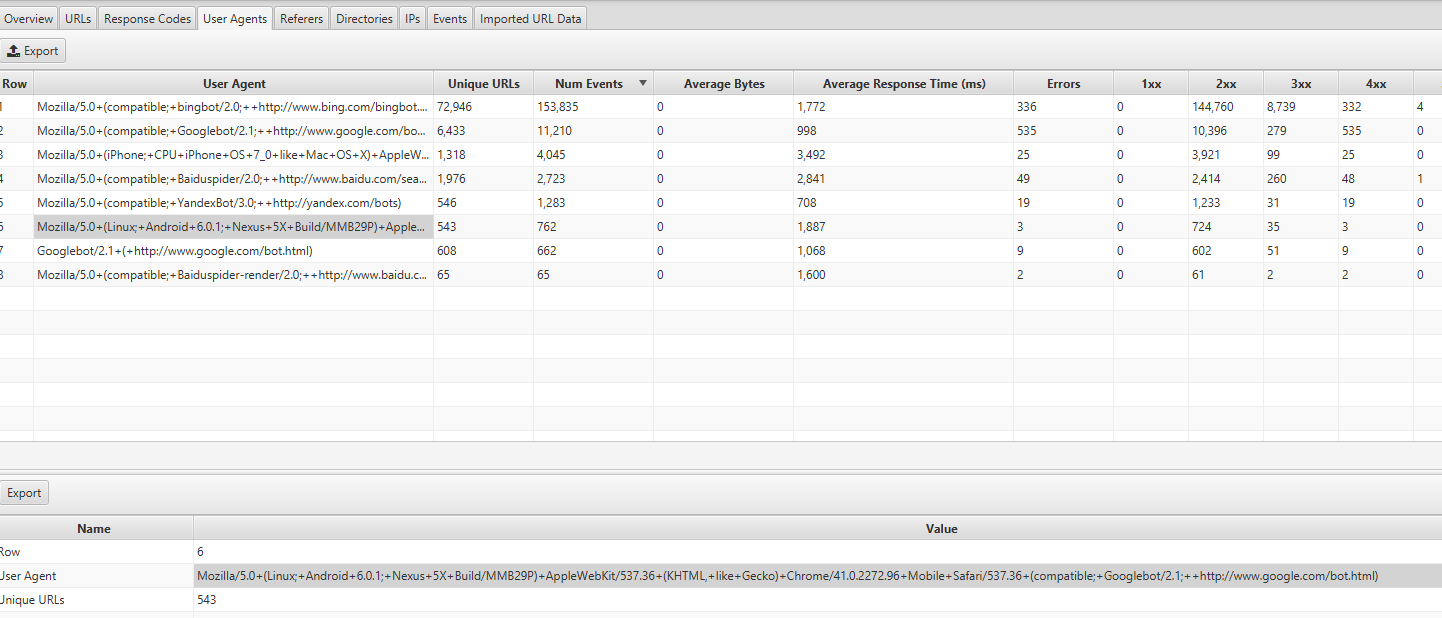
Puteți găsi aceste informații uitându-vă la fila Agenți utilizator din Screaming Frog Log Analyzer - ar trebui să vedeți majoritatea evenimentelor provenite de la Mozilla / 5.0 (Linux; Android 6.0.1; Nexus 5X Build / MMB29P) cum ar fi Gecko) Chrome / 41.0.2272.96 Mobile Safari / 537.36 (compatibil; Googlebot / 2.1; + http: //www.google.com/bot.html:
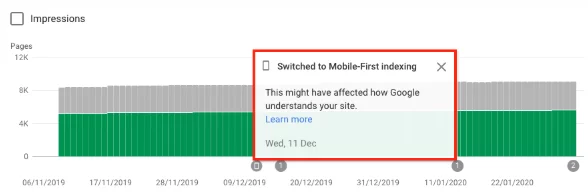
Dacă ați fost schimbat, ar fi trebuit să primiți și o notificare în Consola de căutare Google că site-ul dvs. a avut activată prima indexare pe mobil. Alternativ, puteți vedea acest lucru și în raportul de acoperire.
4. Toți robotii dvs. de motor de căutare vizați vă accesează paginile?
Lipindu-se de roboți, aceasta este o verificare ușoară de efectuat. Știm că Google este motorul de căutare dominant și, prin urmare, asigurarea că Googlebot Smartphone și Googlebot vă vizitează în mod regulat site-ul web ar trebui să fie prioritatea dvs.
Putem filtra datele fișierului jurnal după botul motorului de căutare.
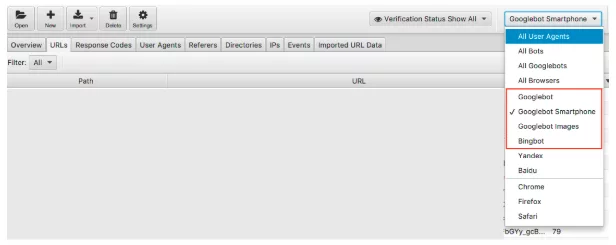
Odată filtrat, puteți căuta să vedeți numărul de evenimente pe care le înregistrează fiecare robot dorit al motorului dvs. de căutare. Sperăm că veți vedea cel mai mult Smartphone-ul Googlebot sau Googlebot care vă vizitează site-ul.
Aș recomanda, de asemenea, să verificați cât de mult vă vizitează site-ul web fiecare bot nedorit. De exemplu, dacă sunteți o companie britanică fără dorința de a vinde bunuri sau servicii către Rusia sau China, puteți vedea cât de mult vizitează site-ul dvs. roboții Yandex și Baidu. Dacă vizitează o sumă neobișnuită (am văzut în unele cazuri că vizitează mai mult decât Googlebot Smartphone) puteți continua și bloca crawlerele din robot.txt.

5. Localizarea codurilor de stare incorecte
În timp ce primim o tonă de date în raportul de acoperire al consolei Căutării Google despre 404s, 200s valide, fișierele jurnal ne oferă o prezentare reală a codurilor de stare ale fiecărei pagini. Numai fișierele jurnal sau trimiterea manuală a preluării și randării Google Search Console vă pot permite să analizați ultimul cod de răspuns pe care motorul de căutare îl va experimenta.
Cu Screaming Frog Log File Analyzer, puteți face acest lucru rapid și, deoarece acestea sunt ordonate în funcție de frecvența de accesare cu crawlere, puteți vedea, de asemenea, care sunt potențial cele mai importante adrese URL de remediat.
Pentru a vedea aceste date, puteți filtra aceste informații în fila Coduri de răspuns
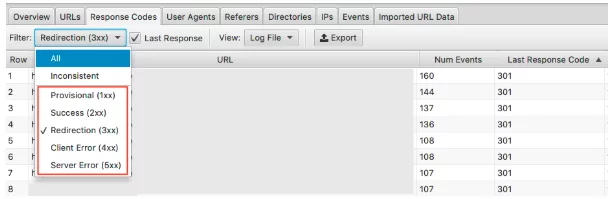
Căutați pagini cu stări HTTP 3xx, 4xx și 5xx
- Sunt vizitați frecvent?
- Sunt vizitate paginile cu 3xx, 4xx și 5xx mai mult decât paginile dvs. importante?
- Există modele în codurile de răspuns?
Cu un proiect, în primele 15 pagini ale acestora cu cele mai multe accesări, au existat redirecționări , redirecționare incorectă 302 (temporară), pagini fără conținut pe ele și unele care erau 404 și soft 404 .
Odată cu analiza fișierului jurnal, odată ce ați identificat problema, puteți începe să o remediați prin actualizarea redirecționărilor incorecte și a soft-urilor 404.
6. Evidențiați codurile de răspuns incoerente
Deși este important să analizați ultimul cod de răspuns pe care motorul de căutare îl va experimenta, evidențierea codurilor de răspuns incoerente vă poate oferi și o perspectivă excelentă.
Dacă v-ați uitat pur și simplu la ultimele coduri de răspuns și nu ați observat erori neobișnuite sau vreun vârf în 4xxs și 5xxs, ați putea încheia verificările tehnice acolo. Cu toate acestea, puteți utiliza un filtru în analizorul de fișiere jurnal pentru a vizualiza în detaliu doar răspunsurile „inconsistente”.

Există multe motive pentru care adresele URL ar putea prezenta coduri de răspuns inconsistente. De exemplu:
- 5xx amestecat cu 2xx - acest lucru poate indica o problemă a serverului atunci când acestea sunt supuse unei încărcări severe.
- 4xx amestecat cu 2xx - acest lucru poate indica linkuri rupte care au apărut sau au fost remediate
După ce aveți la îndemână aceste informații din analiza fișierului jurnal, vă puteți crea planul de acțiune pentru a remedia aceste erori.
7. Auditarea paginilor mari sau lente
Știm timpul până la primul octet (TTFB), timpul până la ultimul octet (TTLB) și timpul până la încărcarea paginii complete influențează modul în care site-ul dvs. este accesat cu crawlere. TTFB, în special, este cheia pentru ca site-ul dvs. să fie accesat cu crawlere rapid și eficient. De asemenea, viteza paginilor fiind un factor de clasificare, putem vedea cât de important este un site web rapid pentru performanța dvs.
Folosind fișiere jurnal putem vedea rapid cele mai mari pagini de pe site-ul dvs. și cele mai lente.
Pentru a vizualiza cele mai mari pagini, sortați coloana „Octeți medii”.
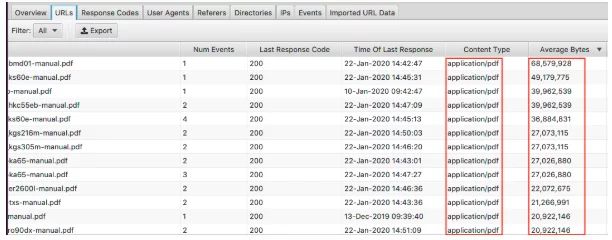
Aici putem vedea PDF-urile care formează cele mai mari pagini de pe site. Optimizarea acestora și reducerea dimensiunii lor sunt un loc minunat pentru a începe. Dacă vedeți că anumite pagini apar aici, vă recomandăm să le priviți individual.
- Sunt acoperite cu imagini de înaltă rezoluție?
- Au videoclipuri redate automat?
- Au fonturi personalizate inutile?
- A fost activată compresia de text?
În timp ce dimensiunea paginii este un bun indicator al unei pagini lente, nu este totul. Puteți avea o pagină mare, dar se poate încărca în continuare rapid. Sortați coloana „Timp mediu de răspuns” și puteți vedea adresele URL cu cel mai lent timp de răspuns.
Ca și în cazul tuturor datelor pe care le vedeți aici, puteți filtra după HTML, JavaScript, Image, CSS și altele, ceea ce este foarte util pentru auditul dvs.
Poate că scopul dvs. este să reduceți dependența site-ului dvs. de JavaScript și doriți să identificați cei mai mari vinovați. Sau știți că CSS poate fi eficientizat și aveți nevoie de date pentru a-l face backup. Site-ul dvs. s-ar putea încărca într-un ritm de melc și filtrarea după imagini vă demonstrează că difuzarea formatelor de generație următoare ar trebui să fie o prioritate.
8. Verificați importanța Link-urilor interne și a adâncimii de crawlere
O altă caracteristică excelentă a acestui analizor de fișiere jurnal este capacitatea de a importa o accesare cu crawlere a site-ului web. Este foarte ușor de făcut și vă oferă mult mai multă flexibilitate în ceea ce puteți analiza din fișierele jurnal. Pur și simplu glisați și fixați crawl-ul în „Date URL importate”, văzut mai jos.
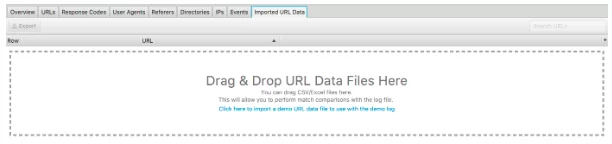
După ce ați făcut acest lucru, puteți face analize suplimentare.
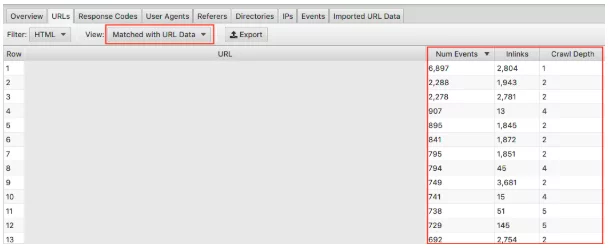
Asigurați-vă că selectați în meniul derulant „Potrivit cu date URL” și trageți coloanele relevante în vizualizare. Aici putem face analize în bloc asupra impactului pe care adâncimea de crawlere și link-urile îl au asupra frecvenței de crawlere a site-ului dvs. web.
De exemplu, dacă aveți pagini „importante” care nu sunt accesate cu crawlere frecvent și observați că au foarte puține linkuri și adâncimea de accesare cu crawlere este mai mare de 3, acesta este cel mai probabil motivul pentru care pagina dvs. nu este accesată cu crawlere prea mult. În schimb, dacă aveți o pagină care este accesată cu crawlere și nu sunteți sigur de ce, uitați-vă unde se află pe site-ul dvs. Unde este legat? Cât de departe este de rădăcină? Analizând acest lucru vă putem indica ce îi place Google despre structura site-ului dvs. În cele din urmă, această tehnică vă poate ajuta să identificați orice probleme legate de ierarhie și structura site-ului.
9. Descoperiți paginile orfane
În cele din urmă, cu datele de accesare cu crawlere importate, identificarea paginilor orfane este ușoară. Paginile orfane pot fi definite ca pagini pe care motoarele de căutare le cunosc, care se accesează cu crawlere, dar nu sunt conectate intern pe site-ul dvs. web.
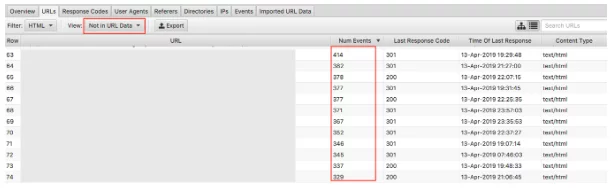
Selectând meniul derulant „Nu în datele URL” se vor afișa adresele URL care sunt prezente în jurnale, dar nu și în datele de accesare cu crawlere . Prin urmare, adresele URL care apar aici vor fi pagini pe care roboții motoarelor de căutare încă le consideră valoroase, dar nu mai apar așa pe site. Adresele URL orfane pot apărea din mai multe motive, inclusiv:
- Modificări ale structurii site-ului
- Actualizări de conținut
- Adrese URL redirecționate vechi
- Conectare internă incorectă
- Conectare externă incorectă
În cele din urmă, trebuie să revizuiți adresele URL ale orfanilor pe care le găsiți și să faceți apel la ce să faceți cu ele.
Gânduri finale
Deci, aceasta este scurta mea introducere în analiza fișierelor jurnal și 9 sarcini care pot fi acționate, pe care le puteți începe imediat cu Screaming Frog Log File Analyzer. Puteți face mult mai mult, atât în Excel, cât și cu celelalte instrumente menționate mai sus (plus altele). Mai mult decât pot acoperi aici! Mai jos sunt câteva resurse pe care le-am găsit utile:
7 întrebări SEO tehnice fundamentale la care să răspundeți printr-o analiză a fișierului jurnal
Ghidul final pentru analiza fișierelor jurnal
Valoarea analizei fișierelor jurnal
Și mai sunt multe de citit, care ar trebui să-i satisfacă pe cei mai curioși dintre pasionații de SEO tehnici!
Cum efectuați analiza fișierului jurnal? Ce instrumente considerați că funcționează cel mai bine? Echipa noastră SEO ar dori să știe. Comenteaza mai jos.
Tocmai ai învățat ceva nou?
Apoi, alăturați-vă celor 80.000 de oameni care citesc în fiecare lună articolele noastre de experți.Dacă aveți nevoie de ajutor pentru SEO, nu ezitați să ne contactați.