
日志文件分析:可用于 SEO 的 9 种可行方法
已发表: 2021-07-19在这篇文章中,我们将介绍什么是日志文件、它们为何重要、需要注意什么以及使用哪些工具。 最后,我将给出 9 种可操作的方法,您可以分析它们以进行 SEO。
什么是服务器日志文件?
服务器日志是由服务器自动创建和维护的日志文件(或多个文件),由它执行的活动列表组成。
出于 SEO 的目的,我们关注 Web 服务器日志,其中包含来自人类和机器人的网站页面请求的历史记录。 这有时也称为访问日志,原始数据如下所示:

是的,这些数据起初看起来有点令人困惑和困惑,所以让我们将其分解并更仔细地查看“命中”。
一个例子命中
每个服务器在记录命中方面本质上是不同的,但它们通常提供组织成字段的相似信息。
以下是 Apache Web 服务器的示例命中(这是简化的 - 一些字段已被删除):
50.56.92.47 – – [01/March/2018:12:21:17 +0100] “GET” – “/wp-content/themes/esp/help.php” – “404” “-” “Mozilla/5.0 (兼容;Googlebot/2.1;+http://www.google.com/bot.html)” – www.example.com –
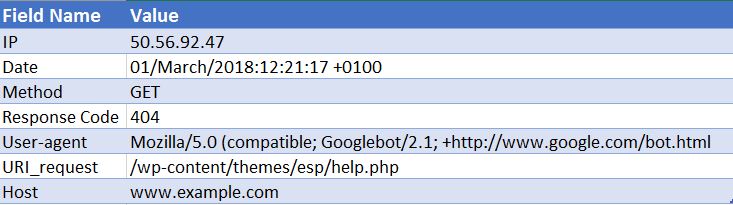
如您所见,对于每次点击,我们都会获得关键信息,例如日期和时间、请求 URI 的响应代码(在本例中为 404)以及请求来自的用户代理(在本例中为 Googlebot )。 可以想象,日志文件每天由数千次点击组成,因为每次用户或机器人到达您的网站时,都会为每个请求的页面记录许多点击 - 包括图像、CSS 和呈现所需的任何其他文件页。
为什么它们很重要?
所以您知道什么是日志文件,但为什么值得花时间分析它们?
嗯,事实是,关于搜索引擎(例如 Googlebot)如何处理您的网站,只有一项真实记录。 那是通过查看您网站的服务器日志文件。
Search Console、第 3 方抓取工具和搜索运营商不会向我们提供有关 Googlebot 和其他搜索引擎如何与网站交互的全貌。 只有访问日志文件才能为我们提供此信息。
我们如何使用日志文件分析进行 SEO?
日志文件分析为我们提供了大量有用的见解,包括使我们能够:
- 准确验证可以或不能抓取的内容。
- 查看搜索引擎在抓取过程中遇到的响应,例如 302、404、软 404。
- 确定可能具有更广泛的基于站点的影响(例如层次结构或内部链接结构)的爬网缺陷。
- 查看搜索引擎优先考虑哪些页面,并可能认为最重要。
- 发现爬行预算浪费的领域。
我将带您完成在日志文件分析期间可以执行的一些任务,并向您展示它们如何为您的网站提供可操作的见解。
如何获取日志文件?
对于这种类型的分析,您需要来自您域的所有 Web 服务器的原始访问日志,没有应用过滤或修改。 理想情况下,您需要大量数据才能使分析有价值。 这值得多少天/周,取决于您网站的大小和权限以及它产生的流量。 对于某些站点,一周可能就足够了,对于某些站点,您可能需要一个月或更长时间的数据。
您的 Web 开发人员应该能够为您发送这些文件。 值得在他们发送给您之前询问他们日志是否包含来自多个域和协议的请求,以及它们是否包含在此日志中。 因为如果没有,这将阻止您正确识别请求。 您将无法分辨对 http://www.example.com/ 和 https://example.com/ 的请求之间的区别。 在这些情况下,您应该要求您的开发人员更新日志配置以包含此信息以备将来使用。
我需要使用哪些工具?
如果您是 Excel 高手,那么本指南对于帮助您使用 Excel 格式化和分析日志文件非常有用。 就个人而言,我使用Screaming Frog 日志文件分析器(每年花费 99 美元)。 其用户友好的界面使您可以快速轻松地发现任何问题(尽管可以说您无法获得与使用 Excel 相同的深度或自由度)。 我将带您完成的示例都是使用 Screaming Frog 日志文件分析器完成的。
其他一些工具是 Splunk 和 GamutLogViewer。
为 SEO 分析日志文件的 9 种方法
1. 找出浪费了爬网预算的地方
首先,什么是抓取预算? 谷歌将其定义为:
“将抓取速度和抓取需求放在一起,我们将抓取预算定义为 Googlebot 可以并且想要抓取的 URL 数量。”
从本质上讲 - 它是搜索引擎每次访问您的网站时将抓取的页面数量,并与域的权限相关联,并与通过网站的链接资产流量成正比。
与日志文件分析相关的关键是,爬行预算有时会浪费在不相关的页面上。 如果您有想要编入索引的新内容但没有剩余预算,那么 Google 不会将这些新内容编入索引。 这就是为什么您希望通过日志文件分析来监控您的抓取预算花费在哪里。
影响抓取预算的因素
拥有许多低附加值的 URL 会对网站的抓取和索引编制产生负面影响。 低附加值 URL 可分为以下几类:
- 分面导航、动态 URL 生成和会话标识符(常见于电子商务网站)
- 现场重复内容
- 被黑页面
- 软错误页面
- 低质量和垃圾邮件内容
在这样的页面上浪费服务器资源会消耗真正有价值的页面的爬行活动,这可能会导致在站点上发现好的内容的显着延迟。
例如,查看这些日志文件,我们发现经常访问错误的 WordPress 主题,这是一个明显的修复!

在查看每个页面获得的事件数量时,问问自己 Google 是否应该打扰抓取这些 URL - 您经常会发现答案是否定的。 因此,优化您的抓取预算将有助于搜索引擎抓取您网站上最重要的页面并将其编入索引。 您可以通过多种方式执行此操作,例如通过使用robots.txt 文件阻止包含特定模式的 URL 来排除 URL 被抓取。 查看我们关于该主题的有用帖子。
2.您的重要页面是否被抓取?
我们已经介绍了为什么 Google 不要在您的低价值页面上浪费抓取预算的重要性。 硬币的另一面是检查您的高价值页面是否以您对它们的重视程度被访问。 如果您按事件数排序日志文件并按 HTML 过滤,您可以查看访问量最大的页面。
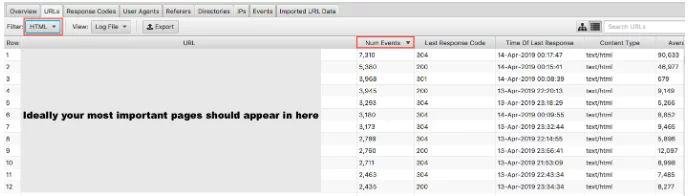
说您最重要的 URL 应该被抓取得最多有点过于简单化了——但是,如果您是一个潜在客户网站,您希望您的主页、关键服务页面和博客内容出现在那里。
作为电子商务网站,您希望您的主页、类别页面和关键产品页面出现在那里。 如果您在这些结果中看到不再销售的旧产品页面,并且最重要的类别页面为零,那么您就有问题了。
3.了解您的网站是否已切换到 Google 的移动优先索引
您可以记录文件分析以了解您的网站是否正在增加 Googlebot 智能手机的抓取,表明它已切换到移动优先索引。 自 2019 年 7 月 1 日起,默认情况下为所有新网站(网络新网站或 Google 搜索之前未知)启用移动优先索引。 谷歌自己已经声明:
“对于较旧的或现有的网站,我们会继续根据本指南中详述的最佳实践来监控和评估页面。 我们会在 Search Console 中通知网站所有者他们的网站切换到移动优先索引的日期。” Google 移动优先索引最佳实践
通常情况下,仍然在常规索引上的网站将有大约 80% 的谷歌抓取由桌面抓取工具完成,20% 由移动抓取工具完成。 您很可能已经切换到移动优先,如果您切换到了,那么 80/20 号码将会反转。
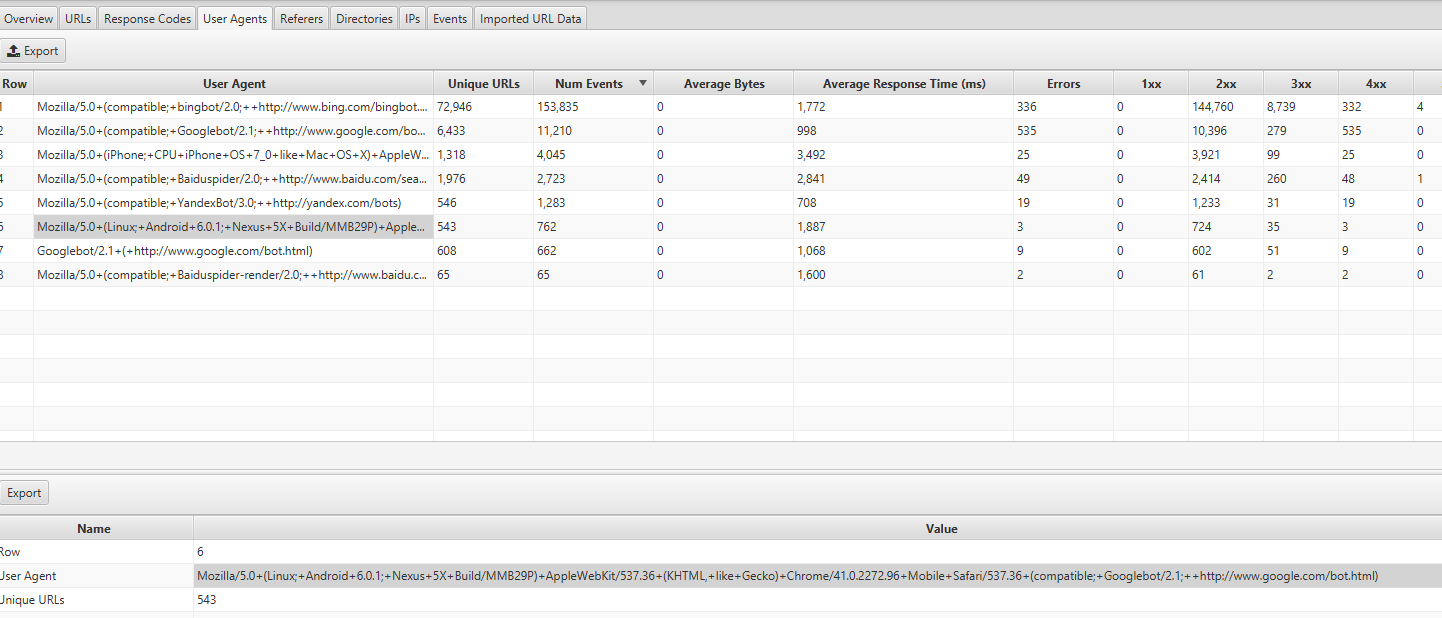
您可以通过查看 Screaming Frog Log Analyzer 中的 User Agents 选项卡来找到此信息——您应该会看到来自 Mozilla/5.0(Linux;Android 6.0.1;Nexus 5X Build/MMB29P)AppleWebKit/537.36(KHTML,像 Gecko)Chrome/41.0.2272.96 Mobile Safari/537.36(兼容;Googlebot/2.1;+http://www.google.com/bot.html:
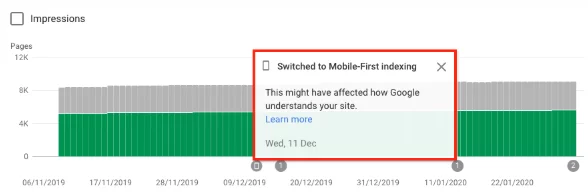
如果您已切换,您还应该在 Google Search Console 中收到通知,说明您的网站已启用移动优先索引。 或者,您也可以在覆盖率报告中看到这一点。
4. 是否所有有针对性的搜索引擎机器人都在访问您的页面?
坚持使用机器人,这是一个很容易执行的检查。 我们知道 Google 是占主导地位的搜索引擎,因此确保 Googlebot 智能手机和 Googlebot 定期访问您的网站应该是您的首要任务。
我们可以通过搜索引擎机器人过滤日志文件数据。
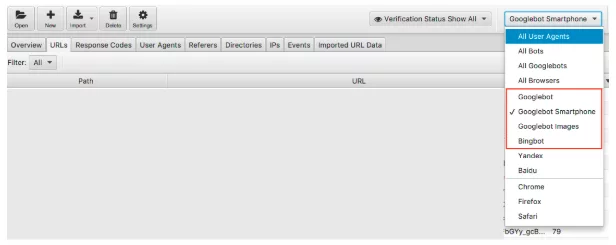
过滤后,您可以查看每个所需搜索引擎机器人正在记录的事件数量。 希望您会看到 Googlebot 智能手机或 Googlebot 最常访问您的网站。
我还建议检查每个不受欢迎的机器人访问您网站的次数。 例如,如果您是一家不希望向俄罗斯或中国销售商品或服务的英国企业,您可以查看 Yandex 和百度机器人访问您网站的数量。 如果他们访问的数量异常(我在某些情况下看到他们访问的次数超过 Googlebot 智能手机),您可以继续阻止 robots.txt 中的抓取工具。
5. 发现错误的状态代码
虽然我们在 Google 搜索控制台覆盖率报告中获得了大量关于 404 秒(有效 200 秒)的数据,但日志文件为我们提供了每个页面状态代码的实际概览。 只有日志文件或手动提交 Google Search Console 的 fetch 和 render 才能让您分析搜索引擎将经历的最后响应代码。
使用 Screaming Frog 日志文件分析器,您可以快速执行此操作,并且由于它们是按抓取频率排序的,因此您还可以查看哪些可能是最重要的需要修复的 URL。
要查看此数据,您可以在响应代码选项卡下过滤此信息
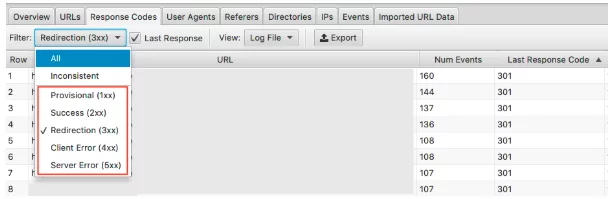
查找具有 3xx、4xx 和 5xx HTTP 状态的页面
- 他们经常被访问吗?
- 访问 3xx、4xx 和 5xx 的页面是否比您的重要页面多?
- 响应代码是否有任何模式?
在一个项目中,在点击次数最多的前 15 个页面中,有重定向、不正确的 302(临时)重定向、没有内容的页面以及一些 404 和软 404 。
通过日志文件分析,一旦确定了问题,您就可以通过更新不正确的重定向和软 404 来开始修复它。
6. 突出显示不一致的响应代码
虽然分析搜索引擎将经历的最后一个响应代码很重要,但突出显示不一致的响应代码也可以让您深入了解。

如果您纯粹查看最后的响应代码并且没有发现 4xxs 和 5xxs 中的异常错误或任何峰值,您可能会在那里结束您的技术检查。 但是,您可以在日志文件分析器中使用过滤器来仅详细查看“不一致”的响应。

您的 URL 可能会遇到不一致的响应代码的原因有很多。 例如:
- 5xx 与 2xx 混合 - 这可能表示服务器在严重负载下出现问题。
- 4xx 与 2xx 混合 - 这可以指向已出现或已修复的断开链接
一旦您掌握了日志文件分析中的这些信息,您就可以制定行动计划来修复这些错误。
7. 审核大页面或慢页面
我们知道第一个字节的时间 (TTFB)、最后一个字节的时间 (TTLB) 和整个页面加载的时间会影响您网站的抓取方式。 TTFB 尤其是让您的网站快速有效地被抓取的关键。 页面速度也是一个排名因素,我们可以看到一个快速的网站对你的表现有多重要。
使用日志文件,我们可以快速查看您网站上最大的页面和最慢的页面。
要查看最大的页面,请对“平均字节数”列进行排序。
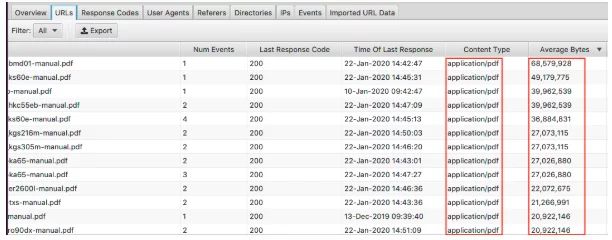
在这里,我们可以看到 PDF 构成了网站上最大的页面。 优化这些并减小它们的大小是一个很好的起点。 如果您看到特定页面出现在此处,您可能需要单独查看它们。
- 它们是否被高分辨率图像覆盖?
- 他们有视频自动播放吗?
- 他们有不必要的自定义字体吗?
- 是否启用了文本压缩?
虽然页面的大小是一个缓慢页面的良好指标,但它并不是一切。 你可以有一个大页面,但它仍然可以快速加载。 对“平均响应时间”列进行排序,您可以看到响应时间最慢的 URL。
与您在此处看到的所有数据一样,您可以按 HTML、JavaScript、图像、CSS 等进行过滤,这对您的审核非常有用。
也许您的目标是减少网站对 JavaScript 的依赖,并希望找出最大的罪魁祸首。 或者您知道 CSS 可以简化并且需要数据来支持它。 您的网站可能会以蜗牛般的速度加载,并且通过图像过滤向您展示了提供下一代格式应该是优先事项。
8. 检查内部链接和抓取深度重要性
此日志文件分析器的另一个重要功能是能够导入网站的爬行。 这真的很容易做到,并且在您可以从日志文件中分析的内容方面为您提供了更大的灵活性。 只需将抓取拖放到下面看到的“导入的 URL 数据”中。
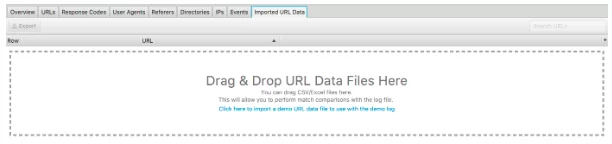
完成后,您可以进行进一步的分析。
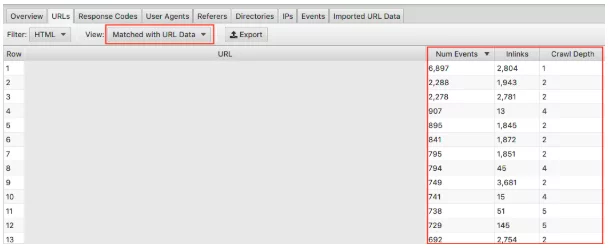
确保在下拉菜单中选择“与 URL 数据匹配”并将相关列拖到视图中。 在这里我们可以批量分析抓取深度和内链对您网站抓取频率的影响。
例如,如果您的“重要”页面不经常被抓取,并且您发现它们的内链很少并且抓取深度大于 3,这很可能是您的页面没有被抓取太多的原因。 相反,如果您有一个页面被大量抓取而您不确定原因,请查看它在您网站中的位置。 它在哪里链接? 离根有多远? 分析这一点可以向您表明 Google 喜欢您的网站结构。 最终,这种技术可以帮助您识别层次结构和站点结构的任何问题。
9. 发现孤立页面
最后,导入抓取数据后,发现孤立页面很容易。 孤立页面可以定义为搜索引擎知道并且正在爬行但未在您的网站内部链接到的页面。
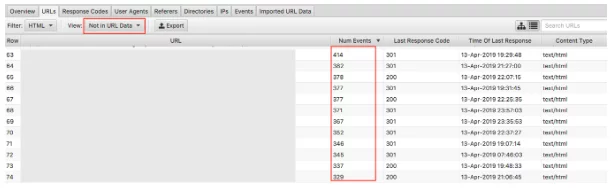
选择“不在 URL 数据中”下拉菜单将显示存在于日志中但不在您的抓取数据中的 URL 。 因此,出现在这里的 URL 将是搜索引擎机器人仍然认为有价值的页面,但不再出现在网站上。 出现孤立 URL 的原因有很多,包括:
- 网站结构变化
- 内容更新
- 旧的重定向 URL
- 内部链接不正确
- 错误的外部链接
最终,您需要查看找到的孤立 URL 并判断如何处理它们。
最后的想法
以上就是我对日志文件分析和 9 个可操作任务的简要介绍,您可以使用 Screaming Frog 日志文件分析器立即开始。 无论是在 Excel 中还是使用上述其他工具(以及其他工具),您都可以做更多的事情。 比我在这里所能涵盖的更多! 以下是我发现有用的一些资源:
用日志文件分析回答 7 个基本的 SEO 技术问题
日志文件分析终极指南
日志文件分析的价值
还有更多内容可供阅读,应该可以满足最好奇的技术 SEO 爱好者!
如何进行日志文件分析? 你觉得什么工具最有效? 我们的 SEO 团队很想知道。 在下面评论。
你刚学到新东西吗?
然后加入每月阅读我们专家文章的 80,000 人的行列。如果您需要 SEO 方面的帮助,请随时与我们联系。