
Analyse des fichiers journaux : 9 manières pratiques de l'utiliser pour le référencement
Publié: 2021-07-19Dans cet article, nous verrons ce que sont les fichiers journaux, pourquoi ils sont importants, ce qu'il faut rechercher et quels outils utiliser. Enfin, je vais vous donner 9 façons concrètes de les analyser pour le référencement.
Qu'est-ce qu'un fichier journal de serveur ?
Un journal de serveur est un fichier journal (ou plusieurs fichiers) automatiquement créé et maintenu par un serveur composé d'une liste d'activités qu'il a effectuées.
À des fins de référencement, nous sommes concernés par un journal de serveur Web qui contient un historique des demandes de pages pour un site Web, provenant à la fois des humains et des robots. Ceci est également parfois appelé journal d'accès, et les données brutes ressemblent à ceci :

Oui, les données semblent un peu écrasantes et déroutantes au début, alors décomposons-les et examinons un « impact » de plus près.
Un exemple de succès
Chaque serveur est intrinsèquement différent dans la journalisation des hits, mais ils donnent généralement des informations similaires organisées en champs.
Vous trouverez ci-dessous un exemple d'accès à un serveur Web Apache (c'est simplifié - certains champs ont été supprimés) :
50.56.92.47 – – [01/Mars/2018:12:21:17 +0100] "GET" – "/wp-content/themes/esp/help.php" – "404" "-" "Mozilla/5.0 ( compatible ; Googlebot/2.1 ; +http://www.google.com/bot.html)” – www.example.com –
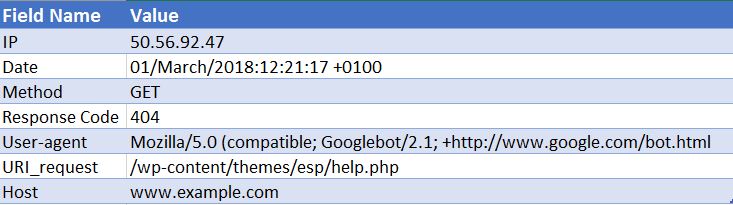
Comme vous pouvez le voir, pour chaque hit, nous recevons des informations clés telles que la date et l'heure, le code de réponse de l'URI demandé (dans ce cas, un 404) et l'agent utilisateur d'où provient la demande (dans ce cas, Googlebot ). Comme vous pouvez l'imaginer, les fichiers journaux sont constitués de milliers de visites chaque jour, car chaque fois qu'un utilisateur ou un bot arrive sur votre site, de nombreuses visites sont enregistrées pour chaque page demandée - y compris les images, CSS et tout autre fichier requis pour rendre le page.
Pourquoi sont-ils significatifs ?
Vous savez donc ce qu'est un fichier journal, mais pourquoi vaut-il la peine de prendre le temps de les analyser ?
Eh bien, le fait est qu'il n'y a qu'un seul véritable enregistrement de la façon dont les moteurs de recherche, tels que Googlebot, traitent votre site Web. Et c'est en examinant les fichiers journaux de votre serveur pour votre site Web.
La console de recherche, les robots d'exploration tiers et les opérateurs de recherche ne nous donneront pas une image complète de la façon dont Googlebot et d'autres moteurs de recherche interagissent avec un site Web. SEULS les fichiers journaux d'accès peuvent nous donner cette information.
Comment pouvons-nous utiliser l'analyse des fichiers journaux pour le référencement ?
L'analyse des fichiers journaux nous donne une énorme quantité d'informations utiles, notamment en nous permettant de :
- Validez exactement ce qui peut ou ne peut pas être exploré.
- Affichez les réponses rencontrées par les moteurs de recherche lors de leur exploration, par exemple 302, 404, 404 logiciels.
- Identifiez les lacunes de l'exploration, qui pourraient avoir des implications plus larges sur le site (telles que la hiérarchie ou la structure des liens internes).
- Voyez quelles pages les moteurs de recherche privilégient et pourraient considérer les plus importantes.
- Découvrez les zones de gaspillage de budget de crawl.
Je vais vous expliquer certaines des tâches que vous pouvez effectuer lors de l'analyse de votre fichier journal et vous montrer comment elles peuvent vous fournir des informations exploitables pour votre site Web.
Comment puis-je obtenir des fichiers journaux ?
Pour ce type d'analyse, vous avez besoin des journaux d'accès bruts de tous les serveurs web de votre domaine, sans filtrage ni modification appliqué. Idéalement, vous aurez besoin d'une grande quantité de données pour que l'analyse en vaille la peine. Le nombre de jours/semaines que cela vaut dépend de la taille et de l'autorité de votre site et de la quantité de trafic qu'il génère. Pour certains sites, une semaine peut suffire, pour certains sites, vous aurez peut-être besoin d'un mois ou plus de données.
Votre développeur Web devrait être en mesure de vous envoyer ces fichiers pour vous. Il vaut la peine de leur demander avant qu'ils ne vous envoient si les journaux contiennent des demandes provenant de plusieurs domaines et protocoles et s'ils sont inclus dans ces journaux. Car sinon, cela vous empêchera d'identifier correctement les demandes. Vous ne pourrez pas faire la différence entre une demande pour http://www.example.com/ et https://example.com/. Dans ces cas, vous devez demander à votre développeur de mettre à jour la configuration du journal pour inclure ces informations à l'avenir.
Quels outils dois-je utiliser ?
Si vous êtes un adepte d'Excel, ce guide est vraiment utile pour vous aider à formater et à analyser vos fichiers journaux à l'aide d'Excel. Personnellement, j'utilise le Screaming Frog Log File Analyzer (coût de 99 $ par an). Son interface conviviale permet de détecter rapidement et facilement tout problème (même si vous n'obtiendrez sans doute pas le même niveau de profondeur ou de liberté que celui que vous gagneriez en utilisant Excel). Les exemples que je vais vous donner sont tous réalisés à l'aide de l'analyseur de fichiers journaux Screaming Frog.
Certains autres outils sont Splunk et GamutLogViewer.
9 façons d'analyser les fichiers journaux pour le référencement
1. Trouvez où le budget de crawl est gaspillé
Tout d'abord, qu'est-ce que le crawl budget ? Google le définit comme :
"En prenant ensemble le taux d'exploration et la demande d'exploration, nous définissons le budget d'exploration comme le nombre d'URL que Googlebot peut et veut explorer."
Essentiellement, c'est le nombre de pages qu'un moteur de recherche explorera chaque fois qu'il visite votre site et est lié à l'autorité d'un domaine et proportionnel au flux d'équité des liens à travers un site Web.
Surtout en ce qui concerne l'analyse des fichiers journaux, le budget de crawl peut parfois être gaspillé sur des pages non pertinentes. Si vous avez du nouveau contenu que vous souhaitez indexer mais qu'il ne vous reste plus de budget, Google n'indexera pas ce nouveau contenu. C'est pourquoi vous souhaitez surveiller où vous dépensez votre budget d'exploration avec l'analyse des fichiers journaux.
Facteurs affectant le budget de crawl
Avoir de nombreuses URL à faible valeur ajoutée peut affecter négativement l'exploration et l'indexation d'un site. Les URL à faible valeur ajoutée peuvent appartenir aux catégories suivantes :
- Navigation à facettes, génération d'URL dynamique et identifiants de session (commun pour les sites Web de commerce électronique)
- Contenu dupliqué sur site
- Pages piratées
- Pages d'erreurs logicielles
- Contenu de mauvaise qualité et spam
Le gaspillage des ressources du serveur sur des pages comme celles-ci drainera l'activité d'exploration des pages qui ont réellement de la valeur, ce qui peut entraîner un retard important dans la découverte d'un bon contenu sur un site.
Par exemple, en regardant ces fichiers journaux, nous avons découvert qu'un thème WordPress incorrect était visité très fréquemment, celui-ci est une solution évidente !

Lorsque vous examinez le nombre d'événements que chaque page reçoit, demandez-vous si Google devrait s'embêter à explorer ces URL . Vous trouverez souvent que la réponse est non. Par conséquent, l'optimisation de votre budget de crawl aidera les moteurs de recherche à explorer et à indexer les pages les plus importantes de votre site Web. Vous pouvez le faire de plusieurs manières, par exemple en excluant l'exploration d'URL en bloquant les URL contenant certains modèles avec le fichier robots.txt . Consultez notre article utile sur le sujet.
2. Vos pages importantes sont-elles explorées ?
Nous avons expliqué pourquoi il est important pour Google de ne pas gaspiller le budget de crawl sur vos pages de faible valeur. Le revers de la médaille est de vérifier que vos pages de grande valeur sont visitées avec l'importance que vous leur accordez. Si vous classez vos fichiers journaux par nombre d'événements et filtrez par HTML, vous pouvez voir quelles sont vos pages les plus visitées.
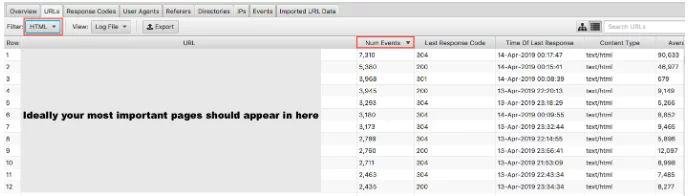
Il serait quelque peu simpliste de dire que vos URL les plus importantes doivent être explorées le plus - cependant, si vous êtes un site de génération de leads, vous voulez que votre page d'accueil, les pages de services clés et le contenu de votre blog y apparaissent.
En tant que site de commerce électronique, vous voudriez que votre page d'accueil, vos pages de catégories et vos pages de produits clés y apparaissent. Si vous voyez une ancienne page de produit que vous ne vendez plus et aucune de vos pages de catégories les plus importantes dans ces résultats, vous avez un problème.
3. Découvrez si votre site est passé à l'index Mobile-First de Google
Vous pouvez enregistrer l'analyse des fichiers pour savoir si votre site Web reçoit l'exploration accrue par Googlebot Smartphone, indiquant qu'il a été basculé vers l' index mobile-first . Depuis le 1er juillet 2019, l'indexation mobile-first est activée par défaut pour tous les nouveaux sites Web (nouveaux sur le Web ou inconnus de la recherche Google). Google lui-même a déclaré :
« Pour les sites Web plus anciens ou existants, nous continuons à surveiller et à évaluer les pages en fonction des meilleures pratiques détaillées dans ce guide. Nous informons les propriétaires de sites dans la Search Console de la date à laquelle leur site est passé à l'indexation mobile-first. Bonnes pratiques d'indexation Google Mobile First
En règle générale, un site toujours sur l'index régulier aura environ 80% de l'exploration de Google effectuée par le robot d'exploration de bureau et 20% par le mobile. Il est fort probable que vous soyez passé au mobile-first, et si c'est le cas, ces chiffres 80/20 s'inverseront.
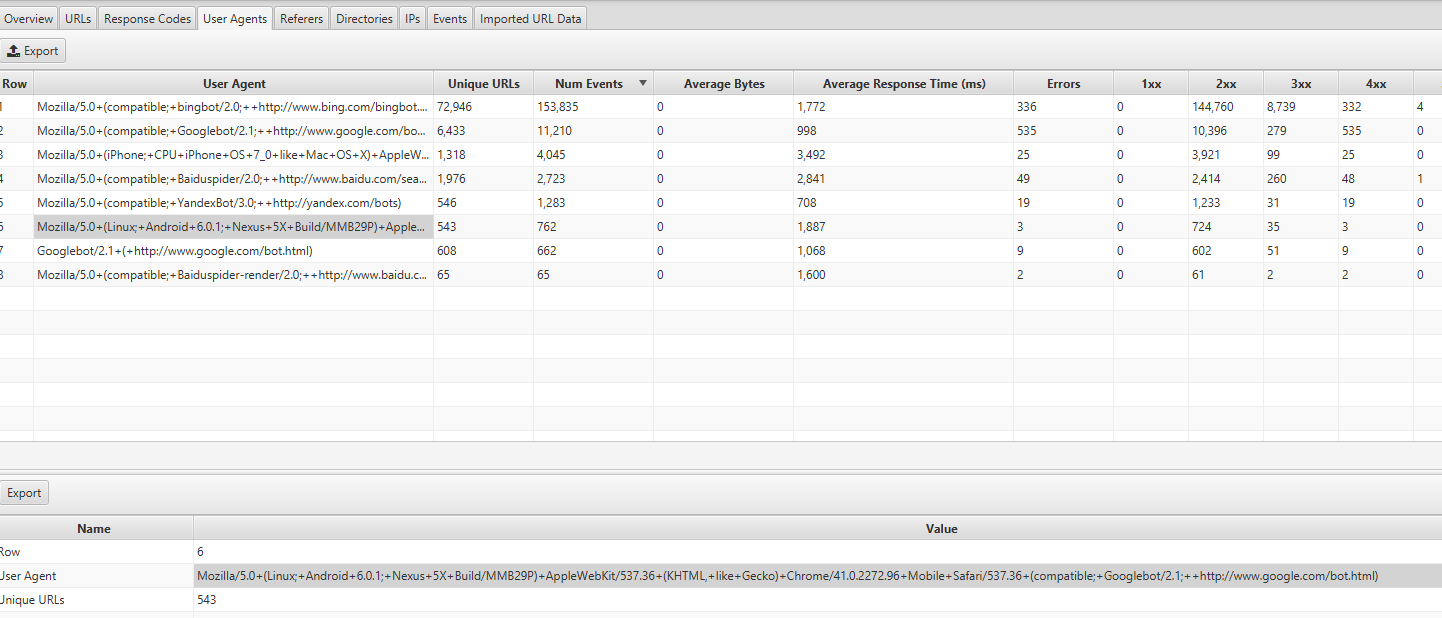
Vous pouvez trouver ces informations en consultant l'onglet User Agents dans Screaming Frog Log Analyzer - vous devriez voir la plupart des événements provenant de Mozilla/5.0 (Linux ; Android 6.0.1 ; Nexus 5X Build/MMB29P) AppleWebKit/537.36 (KHTML, comme Gecko) Chrome/41.0.2272.96 Mobile Safari/537.36 (compatible ; Googlebot/2.1 ; +http://www.google.com/bot.html :
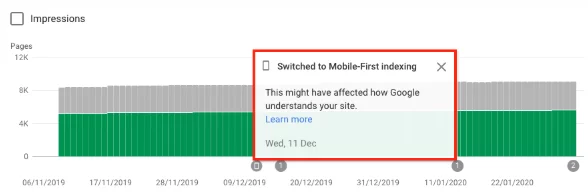
Si vous avez changé, vous devriez également avoir reçu une notification dans la console de recherche Google indiquant que l'indexation mobile-first est activée sur votre site Web. Vous pouvez également le voir dans le rapport de couverture.
4. Tous vos robots de moteur de recherche ciblés accèdent-ils à vos pages ?
S'en tenir aux bots, c'est un contrôle facile à effectuer. Nous savons que Google est le moteur de recherche dominant et donc s'assurer que Googlebot Smartphone et Googlebot visitent régulièrement votre site Web devrait être votre priorité.
Nous pouvons filtrer les données du fichier journal par bot du moteur de recherche.
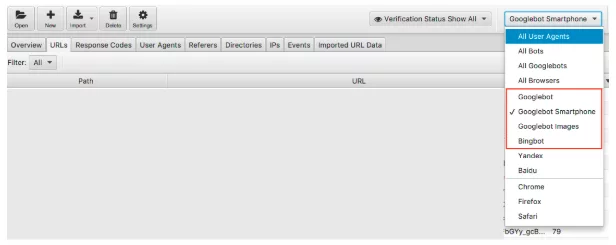
Une fois filtré, vous pouvez regarder pour voir le nombre d'événements que chacun de vos robots de moteur de recherche souhaité enregistre. Espérons que vous verrez le plus souvent le Googlebot Smartphone ou Googlebot visiter votre site.
Je recommanderais également de vérifier combien chaque bot indésirable visite votre site Web. Par exemple, si vous êtes une entreprise britannique qui ne souhaite pas vendre de biens ou de services en Russie ou en Chine, vous pouvez voir combien les robots Yandex et Baidu visitent votre site. S'ils visitent une quantité inhabituelle (j'ai vu dans certains cas qu'ils visitent plus que Googlebot Smartphone), vous pouvez continuer et bloquer les robots d'exploration dans votre robots.txt.

5. Repérer les codes d'état incorrects
Alors que nous obtenons une tonne de données dans le rapport de couverture de la console de recherche Google sur les 404, les 200 valides, les fichiers journaux nous donnent un aperçu réel des codes d'état de chaque page. Seuls les fichiers journaux ou la soumission manuelle de l'extraction et du rendu de Google Search Console peuvent vous permettre d'analyser le dernier code de réponse que le moteur de recherche aura rencontré.
Avec votre analyseur de fichiers journaux Screaming Frog, vous pouvez le faire rapidement et, comme ils sont classés par fréquence d'exploration, vous pouvez également voir quelles sont les URL potentiellement les plus importantes à corriger.
Pour voir ces données, vous pouvez filtrer ces informations sous l'onglet codes de réponse
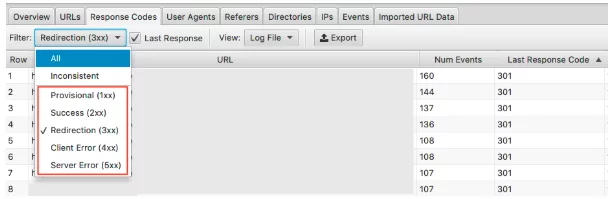
Recherchez les pages avec les statuts HTTP 3xx, 4xx et 5xx
- Sont-ils fréquemment visités ?
- Les pages avec 3xx, 4xx et 5xx sont-elles visitées plus que vos pages importantes ?
- Y a-t-il des modèles dans les codes de réponse ?
Avec un projet, dans leurs 15 premières pages avec le plus de visites, il y avait des redirections , des redirections 302 (temporaires) incorrectes, des pages sans contenu et certaines qui étaient des 404 et des 404 logiciels .
Avec l'analyse de votre fichier journal, une fois que vous avez identifié le problème, vous pouvez commencer à le résoudre en mettant à jour les redirections incorrectes et les soft 404.
6. Mettez en évidence les codes de réponse incohérents
Bien qu'il soit important d'analyser le dernier code de réponse que le moteur de recherche aura connu, la mise en évidence de codes de réponse incohérents peut également vous donner un excellent aperçu.
Si vous n'avez regardé que les derniers codes de réponse et que vous n'avez vu aucune erreur inhabituelle ni aucun pic dans 4xxs et 5xxs, vous pouvez y terminer vos vérifications techniques. Cependant, vous pouvez utiliser un filtre dans l'analyseur de fichier journal pour n'afficher en détail que les réponses « incohérentes ».

Il existe de nombreuses raisons pour lesquelles vos URL peuvent rencontrer des codes de réponse incohérents. Par example:
- 5xx mélangé avec 2xx - cela peut indiquer un problème de serveur lorsqu'ils sont soumis à une charge importante.
- 4xx mélangé avec 2xx - cela peut indiquer des liens brisés qui sont apparus ou ont été corrigés
Une fois que vous disposez de ces informations issues de l'analyse de votre fichier journal, vous pouvez créer votre plan d'action pour corriger ces erreurs.
7. Auditer les pages volumineuses ou lentes
Nous savons que le temps jusqu'au premier octet (TTFB), le temps jusqu'au dernier octet (TTLB) et le temps de chargement complet de la page influencent la façon dont votre site est exploré. TTFB, en particulier, est essentiel pour que votre site soit exploré rapidement et efficacement. La vitesse de la page étant également un facteur de classement, nous pouvons voir à quel point un site Web rapide est crucial pour vos performances.
En utilisant les fichiers journaux, nous pouvons voir rapidement les pages les plus volumineuses de votre site Web et les plus lentes.
Pour afficher vos plus grandes pages, triez la colonne "Average Bytes".
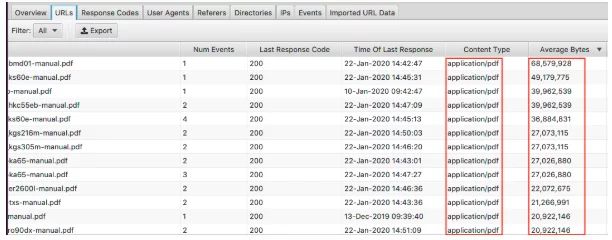
Ici, nous pouvons voir que les PDF constituent les plus grandes pages du site Web. Optimiser ces derniers et réduire leur taille est un excellent point de départ. Si vous voyez des pages particulières apparaître ici, vous voudrez peut-être les regarder individuellement.
- Sont-ils recouverts d'images haute résolution ?
- Ont-ils des vidéos en lecture automatique ?
- Ont-ils des polices personnalisées inutiles ?
- La compression de texte a-t-elle été activée ?
Si la taille de la page est un bon indicateur d'une page lente, ce n'est pas tout. Vous pouvez avoir une grande page mais elle peut toujours se charger rapidement. Triez la colonne « Temps de réponse moyen » et vous pouvez voir les URL avec le temps de réponse le plus lent.
Comme pour toutes les données que vous voyez ici, vous pouvez filtrer par HTML, JavaScript, Image, CSS et plus, ce qui est vraiment utile pour votre audit.
Peut-être que votre objectif est de réduire la dépendance de votre site Web à JavaScript et que vous souhaitez repérer les plus gros coupables. Ou vous savez que le CSS peut être rationalisé et que vous avez besoin des données pour le sauvegarder. Votre site peut se charger à un rythme d'escargot et le filtrage par images vous montre que servir des formats de nouvelle génération devrait être une priorité.
8. Vérifiez l'importance des liens internes et de la profondeur d'exploration
Une autre fonctionnalité intéressante de cet analyseur de fichiers journaux est la possibilité d'importer une analyse du site Web. C'est vraiment facile à faire et vous donne beaucoup plus de flexibilité dans ce que vous pouvez analyser à partir de vos fichiers journaux. Faites simplement glisser et déposez le crawl dans les « Données URL importées » ci-dessous.
Une fois que vous avez fait cela, vous pouvez faire une analyse plus approfondie.
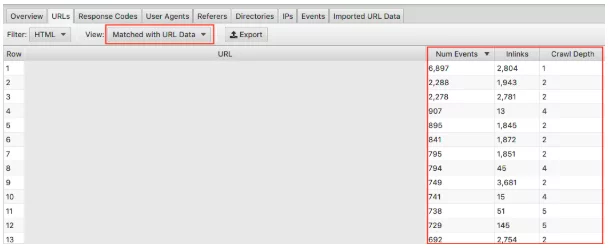
Assurez-vous de sélectionner dans la liste déroulante « Correspondance avec les données d'URL » et faites glisser les colonnes pertinentes dans la vue. Ici, nous pouvons effectuer une analyse globale de l'impact de la profondeur d'exploration et des liens entrants sur la fréquence d'exploration de votre site Web.
Par exemple, si vous avez des pages « importantes » qui ne sont pas explorées fréquemment et que vous remarquez qu'elles ont très peu de liens entrants et que la profondeur d'exploration est supérieure à 3, c'est probablement pourquoi votre page n'est pas beaucoup explorée. Inversement, si vous avez une page qui est beaucoup explorée et que vous ne savez pas pourquoi, regardez où elle se trouve sur votre site. Où est-ce lié ? A quelle distance de la racine est-il ? L'analyse de cela peut vous indiquer ce que Google aime dans la structure de votre site. En fin de compte, cette technique peut vous aider à identifier tout problème lié à la hiérarchie et à la structure du site.
9. Découvrez les pages orphelines
Enfin, avec les données d'exploration importées, il est facile de repérer les pages orphelines. Les pages orphelines peuvent être définies comme des pages que les moteurs de recherche connaissent et explorent mais ne sont pas liées en interne sur votre site Web.
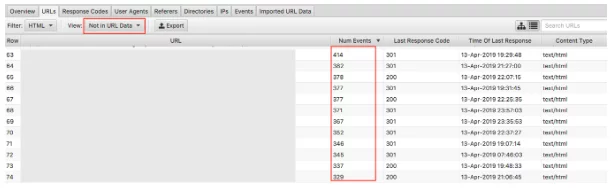
La sélection de la liste déroulante « Pas dans les données d'URL » affichera les URL qui sont présentes dans les journaux mais pas dans vos données d'exploration . Par conséquent, les URL qui apparaissent ici seront des pages que les robots des moteurs de recherche pensent toujours avoir de la valeur, mais n'apparaissent plus ainsi sur le site Web. Les URL orphelines peuvent apparaître pour de nombreuses raisons, notamment :
- Modifications de la structure du site
- Mises à jour du contenu
- Anciennes URL redirigées
- Lien interne incorrect
- Lien externe incorrect
En fin de compte, vous devez examiner les URL des orphelins que vous trouvez et juger de ce qu'il faut en faire.
Dernières pensées
Voilà donc ma brève introduction à l'analyse des fichiers journaux et à 9 tâches exploitables que vous pouvez commencer immédiatement avec l'analyseur de fichiers journaux Screaming Frog. Vous pouvez faire beaucoup plus, à la fois dans Excel et avec les autres outils mentionnés ci-dessus (plus d'autres). Plus que ce que je peux couvrir ici ! Vous trouverez ci-dessous quelques ressources que j'ai trouvées utiles :
7 questions techniques fondamentales sur le référencement auxquelles répondre avec une analyse de fichier journal
Le guide ultime de l'analyse des fichiers journaux
La valeur de l'analyse des fichiers journaux
Et il y a plein d'autres choses à lire qui devraient satisfaire les plus curieux des passionnés de référencement technique !
Comment effectuez-vous l'analyse des fichiers journaux ? Selon vous, quels outils fonctionnent le mieux ? Notre équipe SEO aimerait savoir. Commentaires ci-dessous.
Vous venez d'apprendre quelque chose de nouveau ?
Alors rejoignez les 80 000 personnes qui lisent nos articles d'experts chaque mois.Si vous avez besoin d'aide pour votre référencement, n'hésitez pas à nous contacter.