
Analiza pliku dziennika: 9 praktycznych sposobów, które można wykorzystać do SEO
Opublikowany: 2021-07-19W tym artykule omówimy, czym są pliki dziennika, dlaczego są istotne, na co zwracać uwagę i jakich narzędzi użyć. Na koniec podam 9 praktycznych sposobów ich analizy pod kątem SEO.
Co to jest plik dziennika serwera?
Dziennik serwera to plik dziennika (lub kilka plików) automatycznie tworzony i utrzymywany przez serwer, składający się z listy wykonanych przez niego czynności.
Dla celów SEO zajmujemy się dziennikiem serwera internetowego, który zawiera historię żądań stron dla witryny, zarówno od ludzi, jak i robotów. Jest to również czasami określane jako dziennik dostępu, a surowe dane wyglądają mniej więcej tak:

Tak, na początku dane wydają się nieco przytłaczające i zagmatwane, więc podzielmy je i przyjrzyjmy się bliżej „trafieniu”.
Przykładowy hit
Każdy serwer jest z natury inny pod względem rejestrowania trafień, ale zazwyczaj podaje podobne informacje, które są zorganizowane w pola.
Poniżej przykładowe trafienie na serwer WWW Apache (jest to uproszczone – niektóre pola zostały usunięte):
50.56.92.47 – – [01/March/2018:12:21:17 +0100] “GET” – “/wp-content/themes/esp/help.php” – “404” “-” “Mozilla/5.0 ( zgodny; Googlebot/2.1; +http://www.google.com/bot.html)” – www.example.com –
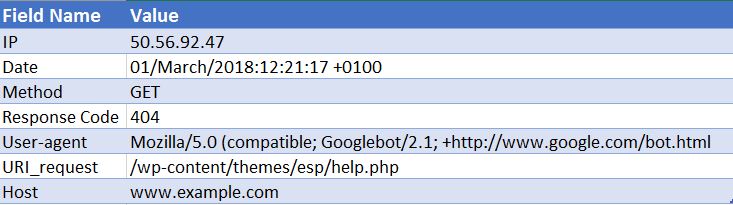
Jak widać, dla każdego działania otrzymujemy kluczowe informacje, takie jak data i godzina, kod odpowiedzi na żądany identyfikator URI (w tym przypadku 404) oraz klienta użytkownika, z którego pochodzi żądanie (w tym przypadku Googlebot ). Jak możesz sobie wyobrazić, pliki dziennika składają się z tysięcy trafień każdego dnia, ponieważ za każdym razem, gdy użytkownik lub bot trafia do Twojej witryny, dla każdej żądanej strony rejestrowanych jest wiele trafień – w tym obrazy, CSS i wszelkie inne pliki wymagane do renderowania strona.
Dlaczego są ważne?
Więc wiesz, co to jest plik dziennika, ale dlaczego warto poświęcić czas na jego analizę?
Cóż, faktem jest, że istnieje tylko jeden prawdziwy zapis tego, jak wyszukiwarki, takie jak Googlebot, przetwarzają Twoją witrynę. I to jest, patrząc na pliki dziennika serwera dla Twojej witryny.
Search Console, roboty indeksujące innych firm i operatorzy wyszukiwania nie dadzą nam pełnego obrazu interakcji Googlebota i innych wyszukiwarek z witryną. TYLKO pliki dziennika dostępu mogą dostarczyć nam tych informacji.
Jak możemy wykorzystać analizę plików dziennika do SEO?
Analiza pliku dziennika daje nam ogromną ilość przydatnych informacji, w tym umożliwia nam:
- Sprawdź dokładnie, co można zindeksować, a czego nie.
- Zobacz odpowiedzi napotkane przez wyszukiwarki podczas ich indeksowania, np. 302s, 404s, soft 404s.
- Zidentyfikuj niedociągnięcia indeksowania, które mogą mieć szersze konsekwencje dla witryny (takie jak hierarchia lub wewnętrzna struktura linków).
- Zobacz, które strony są traktowane priorytetowo przez wyszukiwarki i które mogą uznać za najważniejsze.
- Odkryj obszary marnotrawstwa budżetowego.
Przeprowadzę Cię przez niektóre z zadań, które możesz wykonać podczas analizy pliku dziennika i pokażę Ci, w jaki sposób mogą one dostarczyć Ci przydatnych informacji na temat Twojej witryny.
Jak zdobyć pliki dziennika?
Do tego typu analizy potrzebujesz nieprzetworzonych dzienników dostępu ze wszystkich serwerów internetowych w Twojej domenie, bez filtrowania lub modyfikacji. Najlepiej byłoby, gdyby potrzebna była duża ilość danych, aby analiza była opłacalna. Ile dni/tygodni ma to wartość, zależy od rozmiaru i autorytetu Twojej witryny oraz ilości generowanego przez nią ruchu. W przypadku niektórych witryn wystarczy tydzień, w przypadku niektórych może być potrzebny miesiąc lub więcej danych.
Twój programista internetowy powinien być w stanie wysłać Ci te pliki. Warto zapytać ich, zanim prześlą do Ciebie, czy dzienniki zawierają żądania z więcej niż jednej domeny i protokołu oraz czy są uwzględnione w tych dziennikach. Ponieważ jeśli nie, uniemożliwi to prawidłową identyfikację żądań. Nie będzie można odróżnić żądania adresu http://www.example.com/ od https://example.com/. W takich przypadkach należy poprosić programistę o zaktualizowanie konfiguracji dziennika w celu uwzględnienia tych informacji na przyszłość.
Jakich narzędzi potrzebuję?
Jeśli jesteś znawcą programu Excel, ten przewodnik jest naprawdę przydatny, ponieważ pomaga w formatowaniu i analizowaniu plików dziennika za pomocą programu Excel. Osobiście używam analizatora plików dziennika Screaming Frog (koszt 99 USD rocznie). Przyjazny dla użytkownika interfejs umożliwia szybkie i łatwe wykrywanie wszelkich problemów (chociaż prawdopodobnie nie uzyskasz takiego samego poziomu głębi i swobody, jaki można uzyskać, korzystając z programu Excel). Wszystkie przykłady, przez które cię przeprowadzę, zostały wykonane za pomocą analizatora plików dziennika Screaming Frog.
Niektóre inne narzędzia to Splunk i GamutLogViewer.
9 sposobów analizy plików dziennika pod kątem SEO
1. Znajdź, gdzie marnuje się budżet na indeksowanie
Po pierwsze, czym jest budżet indeksowania? Google definiuje to jako:
„Biorąc razem szybkość indeksowania i zapotrzebowanie na indeksowanie, budżet indeksowania definiujemy jako liczbę adresów URL, które Googlebot może i chce zaindeksować”.
Zasadniczo – jest to liczba stron, które wyszukiwarka będzie indeksować za każdym razem, gdy odwiedza Twoją witrynę i jest powiązana z autorytetem domeny i proporcjonalna do przepływu kapitału linków przez witrynę.
Co ważne w odniesieniu do analizy plików logów, czasami budżet indeksowania może zostać zmarnowany na nieistotne strony. Jeśli masz nowe treści, które chcesz zindeksować, ale nie masz już budżetu, Google nie zindeksuje tej nowej treści. Dlatego chcesz monitorować, gdzie wydajesz budżet na indeksowanie, za pomocą analizy pliku dziennika.
Czynniki wpływające na budżet indeksowania
Posiadanie wielu adresów URL o niskiej wartości dodanej może negatywnie wpłynąć na pobieranie i indeksowanie witryny. Adresy URL o niskiej wartości dodanej mogą należeć do tych kategorii:
- Aspektowa nawigacja, dynamiczne generowanie adresów URL i identyfikatory sesji (typowe dla witryn e-commerce)
- Duplikaty treści na stronie
- Zhakowane strony
- Strony błędów miękkich
- Niska jakość i treści spamowe
Marnowanie zasobów serwera na takich stronach spowoduje zmniejszenie aktywności indeksowania stron, które rzeczywiście mają wartość, co może spowodować znaczne opóźnienie w wykrywaniu dobrej treści w witrynie.
Na przykład, patrząc na te pliki dziennika, odkryliśmy, że nieprawidłowy motyw WordPress był bardzo często odwiedzany, ten jest oczywistą poprawką!

Patrząc na liczbę zdarzeń, które otrzymuje każda strona, zadaj sobie pytanie, czy Google powinno zawracać sobie głowę indeksowaniem tych adresów URL – często znajdziesz odpowiedź „nie”. Dlatego optymalizacja budżetu indeksowania pomoże wyszukiwarkom indeksować i indeksować najważniejsze strony w Twojej witrynie. Możesz to zrobić na kilka sposobów, na przykład wykluczając adresy URL z indeksowania, blokując adresy URL zawierające określone wzorce w pliku robots.txt . Sprawdź nasz przydatny post na ten temat.
2. Czy Twoje ważne strony w ogóle są indeksowane?
Omówiliśmy, dlaczego ważne jest, aby Google nie marnowało budżetu indeksowania na stronach o niskiej wartości. Drugą stroną medalu jest sprawdzenie, czy Twoje strony o wysokiej wartości są odwiedzane z wagą, jaką im przypisujesz. Jeśli uporządkujesz pliki dziennika według liczby zdarzeń i filtrujesz według kodu HTML, możesz zobaczyć, które strony są najczęściej odwiedzane.
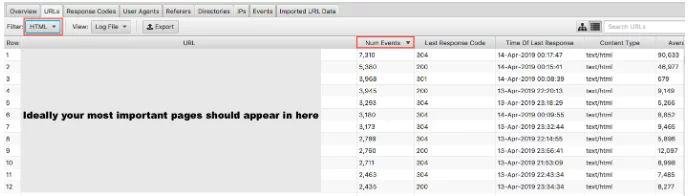
Byłoby nieco uproszczeniem stwierdzenie, że najważniejsze adresy URL powinny być indeksowane najczęściej – jeśli jednak prowadzisz witrynę wiodącej generacji, chcesz, aby pojawiła się tam Twoja strona główna, kluczowe strony usług i treść bloga.
Jako witryna e-commerce chcesz, aby pojawiła się tam Twoja strona główna, strony kategorii i kluczowe strony produktów. Jeśli widzisz starą stronę produktu, której już nie sprzedajesz, i zero najważniejszych stron kategorii w tych wynikach, oznacza to, że masz problem.
3. Dowiedz się, czy Twoja witryna przeszła na indeks Google Mobile-First
Możesz przeprowadzić analizę pliku dziennika, aby dowiedzieć się, czy Twoja witryna jest coraz częściej indeksowana przez Googlebot Smartphone, co wskazuje, że została przełączona na indeks mobile-first . Od 1 lipca 2019 r. indeksowanie zoptymalizowane pod kątem urządzeń mobilnych jest domyślnie włączone dla wszystkich nowych witryn internetowych (nowych w sieci lub wcześniej nieznanych w wyszukiwarce Google). Sami Google stwierdzili:
„W przypadku starszych lub istniejących witryn nadal monitorujemy i oceniamy strony w oparciu o najlepsze praktyki opisane w tym przewodniku. Informujemy właścicieli witryn w Search Console o dacie przełączenia ich witryny na indeksowanie zoptymalizowane pod kątem urządzeń mobilnych”. Sprawdzone metody indeksowania Google Mobile-first
Zazwyczaj witryna, która nadal znajduje się w zwykłym indeksie, będzie przeszukiwana w około 80% przez robota na komputery stacjonarne i 20% przez robota mobilnego. Najprawdopodobniej zostałeś przełączony na telefon komórkowy, a jeśli tak, te numery 80/20 zostaną odwrócone.
Możesz znaleźć te informacje, patrząc na zakładkę User Agents w Screaming Frog Log Analyzer – powinieneś zobaczyć większość zdarzeń pochodzących z Mozilli/5.0 (Linux; Android 6.0.1; Nexus 5X Build/MMB29P) AppleWebKit/537.36 (KHTML, jak Gecko) Chrome/41.0.2272.96 Mobile Safari/537.36 (zgodny; Googlebot/2.1; +http://www.google.com/bot.html:
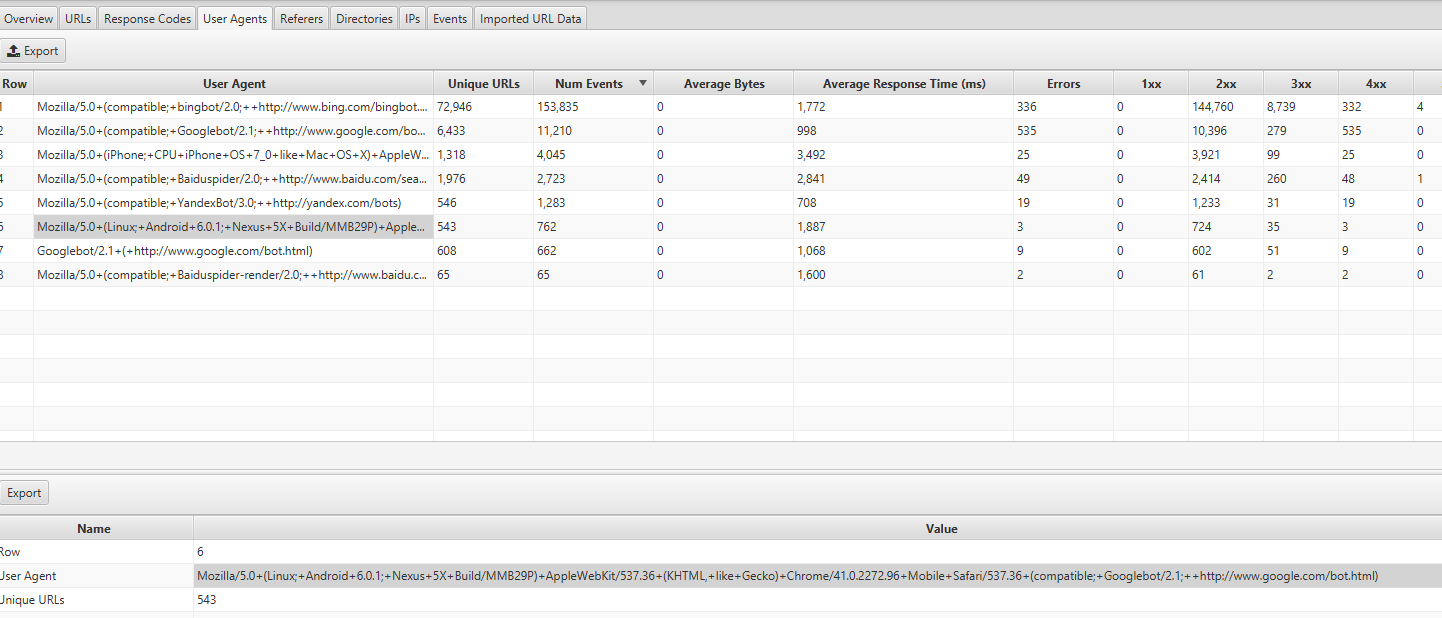
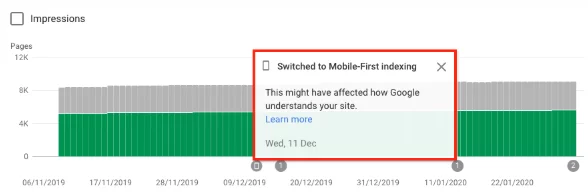
Jeśli zostałeś przełączony, powinieneś otrzymać powiadomienie w Google Search Console, że Twoja witryna ma włączone indeksowanie zoptymalizowane pod kątem urządzeń mobilnych. Możesz też zobaczyć to w raporcie pokrycia.
4. Czy wszystkie Twoje ukierunkowane boty wyszukiwarek uzyskują dostęp do Twoich stron?
Pozostając przy botach, jest to łatwa kontrola do przeprowadzenia. Wiemy, że Google jest dominującą wyszukiwarką, dlatego zapewnienie, że Googlebot Smartfon i Googlebot regularnie odwiedzają Twoją witrynę, powinno być Twoim priorytetem.
Możemy filtrować dane z pliku dziennika według bota wyszukiwarki.
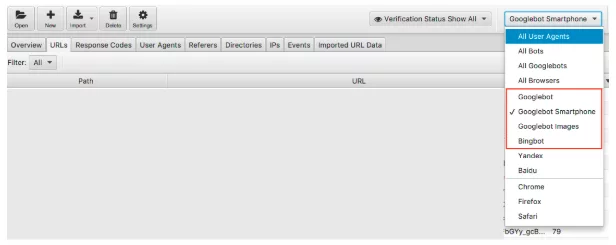
Po przefiltrowaniu możesz sprawdzić, ile zdarzeń rejestruje każdy z wybranych przez Ciebie robotów wyszukiwarek. Mamy nadzieję, że Googlebot Smartfon lub Googlebot będzie najczęściej odwiedzać Twoją witrynę.
Polecam również sprawdzić, ile każdy niepożądany bot odwiedza Twoją witrynę. Na przykład, jeśli prowadzisz brytyjską firmę i nie chcesz sprzedawać towarów ani usług do Rosji lub Chin, możesz zobaczyć, jak często boty Yandex i Baidu odwiedzają Twoją witrynę. Jeśli odwiedzają nietypową liczbę (widziałem, że w niektórych przypadkach odwiedzają więcej niż Googlebot Smartphone), możesz śmiało zablokować roboty w pliku robots.txt.
5. Wykrywanie nieprawidłowych kodów statusu
Podczas gdy w raporcie dotyczącym zasięgu konsoli wyszukiwania Google otrzymujemy mnóstwo danych na temat błędów 404, prawidłowych 200, pliki dziennika dają nam rzeczywisty przegląd kodów stanu każdej strony. Tylko pliki dziennika lub ręczne przesyłanie pobierania i renderowania w Google Search Console umożliwiają przeanalizowanie ostatniego kodu odpowiedzi, jaki napotka wyszukiwarka.

Dzięki analizatorowi plików dziennika Screaming Frog możesz to zrobić szybko, a ponieważ są one uporządkowane według częstotliwości indeksowania, możesz również zobaczyć, które są potencjalnie najważniejszymi adresami URL do naprawienia.
Aby zobaczyć te dane, możesz filtrować te informacje w zakładce Kody odpowiedzi
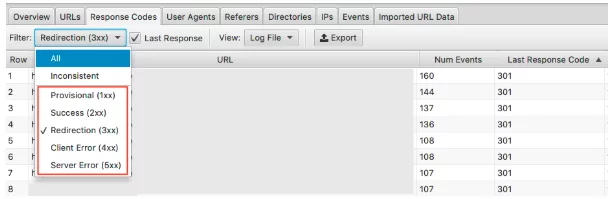
Szukaj stron ze statusami HTTP 3xx, 4xx i 5xx
- Czy są często odwiedzane?
- Czy strony z 3xx, 4xx i 5xx są odwiedzane częściej niż Twoje ważne strony?
- Czy istnieją jakieś wzorce kodów odpowiedzi?
W przypadku jednego projektu, na 15 stronach z największą liczbą odwiedzin, znajdowały się przekierowania , nieprawidłowe przekierowanie 302 (tymczasowe), strony bez treści oraz niektóre z 404 i miękkimi 404 .
Dzięki analizie pliku dziennika, po zidentyfikowaniu problemu, możesz zacząć go naprawiać, aktualizując nieprawidłowe przekierowania i miękkie błędy 404.
6. Zaznacz niespójne kody odpowiedzi
Chociaż ważne jest, aby przeanalizować ostatni kod odpowiedzi, którego doświadczyła wyszukiwarka, wyróżnienie niespójnych kodów odpowiedzi również może dać Ci doskonały wgląd.
Jeśli spojrzałeś wyłącznie na kody ostatniej odpowiedzi i nie zauważyłeś żadnych nietypowych błędów ani żadnych skoków w 4xxs i 5xxs, możesz zakończyć kontrolę techniczną tam. Można jednak użyć filtru w analizatorze plików dziennika, aby wyświetlić szczegółowe tylko odpowiedzi „niespójne”.

Istnieje wiele powodów, dla których w Twoich adresach URL mogą występować niespójne kody odpowiedzi. Na przykład:
- 5xx zmieszany z 2xx – może to wskazywać na problem z serwerem, gdy są one mocno obciążone.
- 4xx zmieszane z 2xx – może to wskazywać na uszkodzone linki, które pojawiły się lub zostały naprawione
Gdy masz już pod ręką te informacje z analizy pliku dziennika, możesz stworzyć swój plan działania, aby naprawić te błędy.
7. Audytuj duże lub wolne strony
Wiemy, że czas do pierwszego bajtu (TTFB), czas do ostatniego bajtu (TTLB) i czas do pełnego załadowania strony mają wpływ na sposób indeksowania witryny. W szczególności TTFB jest kluczem do szybkiego i skutecznego indeksowania witryny. Ponieważ szybkość strony jest również czynnikiem rankingowym, możemy zobaczyć, jak ważna jest szybka strona internetowa dla Twojej wydajności.
Korzystając z plików dziennika, możemy szybko zobaczyć największe strony w Twojej witrynie i te najwolniejsze.
Aby wyświetlić największe strony, posortuj kolumnę „Średnia liczba bajtów”.
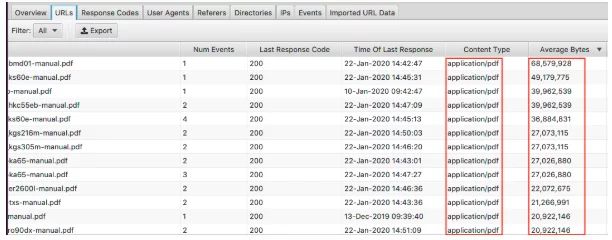
Tutaj widzimy, że pliki PDF tworzą największe strony w witrynie. Zoptymalizowanie ich i zmniejszenie ich rozmiaru to świetny początek. Jeśli widzisz, że pojawiają się tutaj konkretne strony, możesz przyjrzeć się im indywidualnie.
- Czy są pokryte obrazami o wysokiej rozdzielczości?
- Czy mają automatycznie odtwarzane filmy?
- Czy mają niepotrzebne niestandardowe czcionki?
- Czy włączono kompresję tekstu?
Chociaż rozmiar strony jest dobrym wskaźnikiem powolnej strony, to nie wszystko. Możesz mieć dużą stronę, ale nadal może się szybko ładować. Posortuj kolumnę „Średni czas odpowiedzi”, aby zobaczyć adresy URL z najwolniejszym czasem odpowiedzi.
Podobnie jak w przypadku wszystkich danych, które tutaj widzisz, możesz filtrować według HTML, JavaScript, obrazu, CSS i innych, co jest naprawdę przydatne podczas audytu.
Być może Twoim celem jest zmniejszenie zależności Twojej witryny od JavaScript i chęć wykrycia największych winowajców. Lub wiesz, że CSS można uprościć i potrzebujesz danych do utworzenia kopii zapasowej. Twoja witryna może ładować się w ślimaczym tempie, a filtrowanie według obrazów pokazuje, że serwowanie formatów nowej generacji powinno być priorytetem.
8. Sprawdź linki wewnętrzne i znaczenie głębokości indeksowania
Kolejną świetną funkcją tego analizatora plików dziennika jest możliwość importowania indeksowania witryny. Jest to naprawdę łatwe i zapewnia znacznie większą elastyczność w zakresie analizowania danych z plików dziennika. Po prostu przeciągnij i upuść indeksowanie do „Importowanych danych URL” widocznych poniżej.
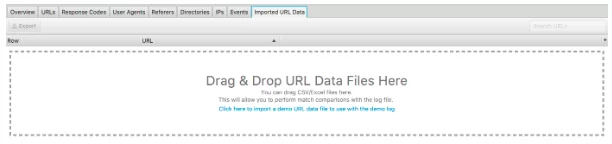
Gdy to zrobisz, możesz przeprowadzić dalszą analizę.
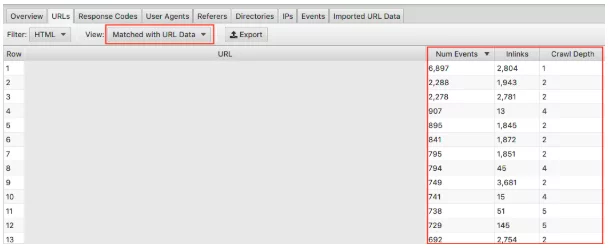
Upewnij się, że wybrałeś z listy rozwijanej „Dopasowane do danych adresu URL” i przeciągnij odpowiednie kolumny do widoku. Tutaj możemy przeprowadzić zbiorczą analizę wpływu głębokości indeksowania i linków na częstotliwość indeksowania Twojej witryny.
Na przykład, jeśli masz „ważne” strony, które nie są często indeksowane i zauważysz, że mają one bardzo mało linków, a głębokość indeksowania przekracza 3, najprawdopodobniej Twoja strona jest rzadko indeksowana. I odwrotnie, jeśli masz stronę, która jest często indeksowana i nie wiesz, dlaczego, spójrz na to, gdzie znajduje się w Twojej witrynie. Gdzie jest powiązany? Jak daleko jest od korzenia? Analiza tego może wskazać, co Google lubi w strukturze Twojej witryny. Ostatecznie ta technika może pomóc w zidentyfikowaniu wszelkich problemów z hierarchią i strukturą witryny.
9. Odkryj strony osierocone
Wreszcie, dzięki zaimportowaniu danych indeksowania, wykrywanie osieroconych stron jest łatwe. Strony osierocone można zdefiniować jako strony, o których wyszukiwarki wiedzą i które indeksują, ale nie są do nich wewnętrznie połączone w Twojej witrynie.
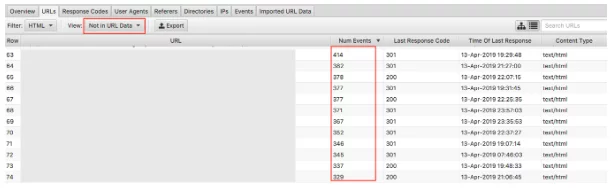
Wybranie menu „Brak w danych URL” spowoduje wyświetlenie adresów URL, które są obecne w dziennikach, ale nie ma ich w danych indeksowania . Dlatego adresy URL, które się tu pojawią, będą stronami, o których boty wyszukiwarek nadal uważają, że mają wartość, ale nie pojawiają się już tak w witrynie. Osierocone adresy URL mogą pojawiać się z wielu powodów, w tym:
- Zmiany w strukturze witryny
- Aktualizacje treści
- Stare przekierowane adresy URL
- Nieprawidłowe połączenie wewnętrzne
- Nieprawidłowe połączenie zewnętrzne
Ostatecznie musisz przejrzeć znalezione adresy URL osieroconych i podjąć decyzję, co z nimi zrobić.
Końcowe przemyślenia
To jest moje krótkie wprowadzenie do analizy plików dziennika i 9 praktycznych zadań, które możesz zacząć od razu dzięki analizatorowi plików dziennika Screaming Frog. Możesz zrobić o wiele więcej, zarówno w programie Excel, jak i za pomocą innych narzędzi wymienionych powyżej (plus inne). Więcej niż mogę tutaj opisać! Poniżej znajdują się niektóre zasoby, które okazały się przydatne:
7 podstawowych pytań technicznych dotyczących SEO, na które należy odpowiedzieć za pomocą analizy pliku dziennika
Kompletny przewodnik po analizie plików dziennika
Wartość analizy plików dziennika
Jest jeszcze wiele do przeczytania, które powinny zadowolić najbardziej ciekawskich entuzjastów SEO!
Jak przeprowadzasz analizę pliku dziennika? Jakie narzędzia sprawdzają się najlepiej? Nasz zespół SEO bardzo chciałby wiedzieć. Komentarz poniżej.
Czy właśnie nauczyłeś się czegoś nowego?
Dołącz do 80 000 osób, które co miesiąc czytają nasze artykuły eksperckie.Jeśli potrzebujesz pomocy w pozycjonowaniu, nie wahaj się z nami skontaktować.